Тестирование темных сценариев вашего Node.js-приложения¶
В статье описываются, какие простые и короткие тесты стоит писать на любое node.js приложение. Хотя в целом это касается не только node.js, но эта статья посвящена именно node.js и есть несколько специфичных кейсов.
Где лежат трупы¶
Этот пост посвящен тестам, которые легко написать, обычно 5-8 строк, они покрывают темные и опасные уголки наших приложений, но часто остаются без внимания.
Сначала немного контекста: как мы тестируем современный бэкенд? С помощью бриллианта тестирования, конечно, делая акцент на компонентных/интеграционных тестах, которые охватывают все слои, включая реальную БД. При таком подходе наши тесты на 99% совпадают с производственными и пользовательскими потоками, а опыт разработки почти такой же, как при использовании юнит-тестов. Если эта тема интересна, мы также написали руководство с 50 лучшими практиками для интеграционных тестов в Node.js.
Но есть один подводный камень: большинство разработчиков пишут только полусчастливые тест-кейсы, ориентированные на основные пользовательские потоки. Например, недействительные вводы, CRUD-операции, различные состояния приложения и т. д. Это действительно хлеб с маслом, отличное начало, но целая область остается непокрытой.
Например, типичные тесты не моделируют необработанный промис, приводящий к аварийному завершению процесса, не моделируют фазу загрузки веб-сервера, которая может завершиться неудачей и оставить процесс без работы, или HTTP-вызовы к внешним сервисам, которые часто завершаются таймаутами и повторными попытками. Они, как правило, не охватывают ни состояние и готовность маршрута, ни целостность OpenAPI к реальной схеме маршрутов, и это лишь несколько примеров. Существует множество "мертвых тел", выходящих за рамки бизнес-логики, которые иногда даже не являются ошибками, а скорее связаны с простоем приложения.
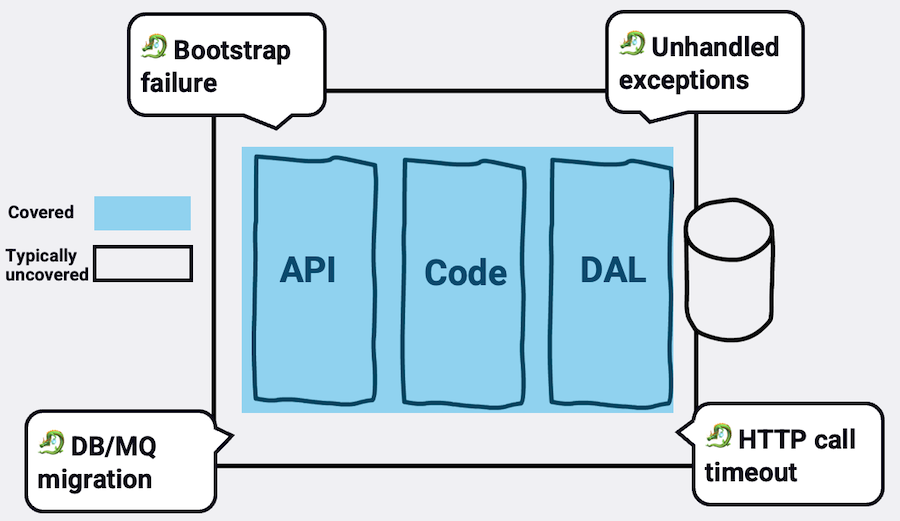
Вот несколько примеров, которые могут открыть вам совершенно новый класс рисков и испытаний
🧟♀️ Тест "Зомби-процесс"¶
👉Что и как?
Во всех своих тестах вы предполагаете, что приложение уже успешно запустилось, не хватает проверки на поток инициализации.
Это очень плохо, так как в этой фазе скрывается несколько потенциально катастрофических сбоев: сбои инициализации происходят часто - здесь может произойти много неприятных вещей, например, обрыв соединения с БД или падение новой версии во время развертывания. По этой причине платформы времени выполнения (например, Kubernetes и другие) поощряют компоненты сигнализировать о своей готовности (см. readiness probe).
Ошибки на этом этапе также оказывают существенное влияние на состояние приложения - если инициализация завершилась неудачно, а процесс остался жив, он становится "зомби-процессом". В этом случае платформа исполнения не поймет, что что-то пошло не так, не переадресует трафик на него и не создаст альтернативных экземпляров. Кроме изящного выхода из процесса, можно рассмотреть возможность протоколирования, срабатывания метрики и корректировки маршрута /readiness.
Работает ли это? Только тест покажет!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
👀 Тест на наблюдаемость¶
👉 Что и зачем
Для многих тестирование ошибок означает проверку типа исключения или ответа API. При этом остается незамеченной одна из самых важных деталей - обеспечение корректной наблюдаемости ошибки.
Проще говоря, убедиться, что она корректно регистрируется и отображается в системе мониторинга. Это может показаться внутренним делом, тестированием реализации, но на самом деле это идет непосредственно к пользователю. Да, не к конечному пользователю, а к другому важному - оперативному пользователю, который находится на связи. Каковы ожидания этого пользователя?
На самом базовом уровне, когда возникает производственная проблема, она должна видеть подробные записи в журнале, включая трассировку стека, причину и другие характеристики. Эта информация может спасти положение при решении производственных инцидентов.
Кроме того, во многих системах мониторинг ведется отдельно, чтобы сделать вывод об общем состоянии системы, используя кумулятивную эвристику (например, увеличение количества ошибок за последние 3 часа). Для поддержки такого мониторинга код также должен снимать метрики ошибок. Даже тесты, которые пытаются покрыть эти потребности, используют наивный подход, проверяя, была ли вызвана функция логгера - но включает ли она правильные данные?
Некоторые пишут более совершенные тесты, которые проверяют тип ошибки, переданной в логгер, - достаточно? Нет! Оперативному пользователю важны не имена классов JavaScript, а отправляемые JSON-данные.
Следующий тест фокусируется на конкретных свойствах, которые становятся наблюдаемыми:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
👽 Тест "нежданный гость" - когда в нашем коде встречается не пойманное исключение¶
👉 Что и почему
Типичный тест потока ошибок ошибочно предполагает два условия: Был брошен корректный объект ошибки, и он был пойман. Ни то, ни другое не гарантировано, давайте сосредоточимся на втором предположении: часто бывает, что некоторые ошибки остаются не пойманными.
Ошибка может быть выброшена до того, как обработчик ошибок вашего фреймворка будет готов, некоторые библиотеки npm могут неожиданно выбрасывать ошибки из разных стеков, используя функции таймера, или вы просто забыли установить someEventEmitter.on('error', ...).
Это лишь несколько примеров. Эти ошибки попадут в глобальный обработчик process.on('uncaughtException'), надеемся, ваш код на них подписался.
Как смоделировать этот сценарий в тесте? Наивно можно найти участок кода, который не обернут try-catch, и заглушить (stub) его, чтобы бросить (throw) во время теста. Но тут возникает загвоздка: если вы знакомы с такой областью, то, скорее всего, вы будете ее исправлять и следить за тем, чтобы ее ошибки перехватывались.
Что же делать? Можно воспользоваться тем, что JavaScript "не имеет границ", если какой-то объект может испускать событие, то мы, как его подписчики, можем сами заставить его испускать это событие, вот пример:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
🕵🏼 Тест на "скрытый эффект" - когда код не должен мутировать вообще¶
👉Что и как
В распространенных сценариях тестируемый код должен останавливаться раньше времени, например, когда входящая полезная нагрузка недействительна или у пользователя недостаточно кредитов для выполнения операции. В этих случаях никакие записи в БД не должны быть изменены.
Большинство тестов ограничиваются проверкой только HTTP-ответа - получили ответ HTTP 400? Отлично, валидация/авторизация, вероятно, работает. Или нет? Тест слишком доверяет коду, корректный ответ не гарантирует, что код, лежащий в основе, ведет себя так, как задумано. Может быть, была добавлена новая запись, хотя у пользователя нет прав? Очевидно, что это нужно проверить, но как проверить, что запись НЕ была добавлена?
Здесь возможны два варианта: Если БД очищается перед/после каждого теста, то просто попробуйте выполнить некорректную операцию и проверьте, что после этого БД пуста. Если же вы чистите БД не часто (как я, но это уже другая тема), то полезная нагрузка должна содержать некоторое уникальное и запрашиваемое значение, которое можно запросить позже и надеяться, что записей не будет. Вот как это выглядит:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
🧨 Тест "переборщил" - когда код должен мутировать, но делает слишком много.¶
👉 Что и почему
Вот как выглядит типичный тест, ориентированный на данные: сначала вы добавляете несколько записей, затем обращаетесь к тестируемому коду, и, наконец, утверждаете, что происходит с этими конкретными записями. Пока все хорошо.
Однако здесь есть одна оговорка: поскольку тест фокусируется на конкретных записях, он не учитывает, были ли излишне затронуты другие записи.
Это может быть очень плохо, вот короткая история из реальной жизни, которая произошла с моим клиентом: в код доступа к данным были внесены изменения, которые привели к ошибке, обновляющей всех пользователей системы, а не только одного. Все тесты пройдены, поскольку они сфокусированы на конкретной записи, которая положительно обновилась, остальные просто проигнорированы.
Как бы вы протестировали и предотвратили это? Вот хороший прием, которому меня научил мой друг Гил Тайар: на первом этапе тестирования, помимо основных записей, добавьте одну или несколько "контрольных" записей, которые не должны изменяться во время тестирования. Затем запускаем тестируемый код и, помимо основного утверждения, проверяем, что контрольные записи не пострадали:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
🕰 Тест "медленный коллаборатор" - когда другой HTTP-сервис работает с перебоями¶
👉 Что и зачем
Когда ваш код обращается к другим сервисам/микросервисам по HTTP, опытные тестировщики сводят к минимуму сквозные тесты, так как в этих тестах прослеживается тенденция к счастливым путям (сложнее моделировать сценарии).
Это обязывает использовать какой-либо mocking-инструмент, чтобы действовать как удаленный сервис, например, с помощью таких инструментов, как nock или wiremock. Эти инструменты хороши, только некоторые используют их наивно и проверяют в основном то, что вызовы извне действительно были сделаны. А что если другой сервис недоступен в производстве, что если он медленнее и периодически выходит из строя (один из самых больших рисков микросервисов)?
Хотя вы не можете полностью спасти эту транзакцию, ваш код должен сделать все возможное в данной ситуации и повторить попытку, или, по крайней мере, зарегистрировать и вернуть правильный статус вызывающему сервису. Все инструменты сетевого мокинга позволяют имитировать задержки, таймауты и другие "хаотичные" сценарии. Остается вопрос, как имитировать медленный отклик, не создавая медленных тестов?
Можно использовать fake timers и обмануть систему, заставив ее поверить в то, что за один тик прошло несколько секунд. Если вы используете nock, то он предлагает интересную возможность имитировать таймауты быстро: функция .delay имитирует медленный ответ, после чего nock сразу поймет, что задержка больше, чем таймаут HTTP-клиента, и сразу, не дожидаясь, выбросит событие таймаута
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
💊 Тест на "отравленное сообщение" - когда потребитель сообщений получает некорректную полезную нагрузку, которая может привести его в состояние стагнации¶
👉 Что и как
При тестировании потоков, которые начинаются или заканчиваются очередью, вы наверняка собираетесь обойти слой очереди сообщений, где код и библиотеки потребляют очередь, и обращаетесь непосредственно к логическому слою.
Да, это упрощает задачу, но оставляет класс неприкрытых рисков. Например, что если логическая часть выкинет ошибку или схема сообщения окажется недействительной, а потребитель очереди сообщений не сможет преобразовать это исключение в соответствующее действие очереди сообщений?
Например, код потребителя может не отклонить сообщение или увеличить количество попыток (зависит от типа используемой очереди). Когда это произойдет, сообщение попадет в цикл, в котором оно будет обслуживаться снова и снова. Поскольку это относится ко многим сообщениям, ситуация может стать очень плохой, так как очередь будет сильно перенасыщена.
По этой причине данный синдром получил название "отравленное сообщение". Чтобы снизить этот риск, область действия тестов должна включать все уровни, как это, вероятно, делается при тестировании API. К сожалению, это не так просто, как тестирование с использованием БД, поскольку очереди сообщений нестабильны, и вот почему.
При тестировании с реальными очередями все становится еще более любопытным: тесты из разных процессов будут красть сообщения друг у друга, очищать очереди сложнее, чем вы думаете (например, SQS требует 60 секунд для очистки очередей), и это только несколько проблем, которые вы не встретите при работе с реальной БД.
Вот стратегия, которая работает во многих командах и является небольшим компромиссом - использовать фальшивую очередь сообщений in-memory. Под "подделкой" я подразумеваю нечто простое, что действует как заглушка/шпион и не делает ничего, кроме как сообщает, когда выполняются определенные вызовы (например, потребление, удаление, публикация).
Вы можете найти авторитетные подделки/шлейфы для вашей собственной очереди сообщений, например этот для SQS, и вы можете сами легко написать такой. Не беспокойтесь, я не сторонник того, чтобы самому поддерживать инфраструктуру тестирования, предлагаемый компонент предельно прост и вряд ли превысит 50 строк кода (см. пример ниже).
В дополнение к этому, независимо от того, используется ли настоящая или фальшивая очередь, необходимо создать удобный интерфейс, сообщающий тесту, когда произошли определенные события, например, когда сообщение было подтверждено/удалено или было опубликовано новое сообщение. Без этого тест никогда не узнает, когда произошли те или иные события, и будет склоняться к таким причудливым методам, как опрос.
При такой настройке тест будет коротким, плоским и вы сможете легко имитировать такие распространенные сценарии работы очереди сообщений, как сообщения не по порядку, пакетный отказ, дублирование сообщений, а в нашем примере - сценарий отравленных сообщений (при использовании RabbitMQ):
-
Создайте поддельную очередь сообщений, которая практически ничего не делает, кроме записи обращений, полный пример см. здесь
1 2 3 4 5 6 7
class FakeMessageQueueProvider extends EventEmitter { // Implement here publish(message) {} consume(queueName, callback) {} } -
Заставьте клиента очереди сообщений принимать реального или фальшивого провайдера (пример простой реализации):
1 2 3 4 5 6 7 8
class MessageQueueClient extends EventEmitter { // Pass to it a fake or real message queue constructor(customMessageQueueProvider) {} publish(message) {} consume(queueName, callback) {} } -
Вывести удобную функцию, которая сообщает, когда были выполнены определенные вызовы
1 2 3 4 5 6 7 8 9 10 11
class MessageQueueClient extends EventEmitter { publish(message) {} consume(queueName, callback) {} // 👇 waitForEvent( eventName: 'publish' | 'consume' | 'acknowledge' | 'reject', howManyTimes: number ) : Promise } -
Тест стал коротким, ровным и выразительным 👇
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
const FakeMessageQueueProvider = require('./libs/fake-message-queue-provider'); const MessageQueueClient = require('./libs/message-queue-client'); const newOrderService = require('./domain/newOrderService'); test( 'When a poisoned message arrives,' + ' then it is being rejected back', async () => { // Arrange const messageWithInvalidSchema = { nonExistingProperty: 'invalid❌', }; const messageQueueClient = new MessageQueueClient( new FakeMessageQueueProvider() ); // Subscribe to new messages and passing the handler function messageQueueClient.consume( 'orders.new', newOrderService.addOrder ); // Act await messageQueueClient.publish( 'orders.new', messageWithInvalidSchema ); // Now all the layers of the app will get stretched 👆, // including logic and message queue libraries // Assert await messageQueueClient.waitFor('reject', { howManyTimes: 1, }); // 👆 This tells us that eventually our code asked // the message queue client to reject this poisoned message } );
📝 Полный пример кода находится здесь
📦 Тестирование пакета как потребителя¶
👉Что и почему
При публикации библиотеки на npm, все ваши тесты могут пройти, но... на компьютере конечного пользователя эта же функциональность не будет работать. Как это происходит? Тесты выполняются над локальными файлами разработчика, а конечному пользователю доступны только артефакты, которые были собраны.
Видите ли вы здесь несоответствие? После выполнения тестов файлы пакета транспонируются (я смотрю на вас, пользователи babel), запечатываются и упаковываются. Если хоть один файл исключен из-за .npmignore или полифилл добавлен некорректно, то в опубликованном коде будут отсутствовать обязательные файлы
Рассмотрим следующий сценарий: вы разрабатываете библиотеку и написали такой код:
1 2 3 4 5 6 7 | |
Затем несколько тестов:
1 2 3 4 5 6 7 | |
Наконец, настройте файл package.json:
1 2 3 4 | |
Видите, покрытие 100%, все тесты пройдены локально и в CI ✅, только в продакшене это не работает 👹. Почему? Потому что вы забыли включить calculate.js в массив файлов package.json 👆.
Что мы можем сделать вместо этого? Мы можем протестировать библиотеку в качестве ее конечных пользователей. Как это сделать? Опубликовать пакет в локальном реестре, например verdaccio, позволить тестам установить и обратиться к опубликованному коду. Звучит хлопотно? Судите сами 👇.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
📝 Полный пример кода находится здесь
Для чего еще может быть полезна эта техника?
- Тестирование различных версий поддерживаемых вами зависимостей - допустим, ваш пакет поддерживает реакцию 16-18, теперь вы можете протестировать это.
- Вы хотите протестировать потребителей ESM и CJS.
- Если у вас есть CLI-приложение, вы можете протестировать его на примере своих пользователей
- Убеждаемся, что вся магия вуду в файле babel работает так, как ожидается
🗞 Тест "нарушенного контракта" - когда код великолепен, но соответствующая документация OpenAPI приводит к ошибке в производстве¶
👉Что и как
С полной уверенностью могу сказать, что практически ни одна команда не проверяет корректность своего OpenAPI. "Это просто документация", "мы генерируем ее автоматически на основе кода" - типичные убеждения, встречающиеся по этой причине. Сейчас я покажу вам, как эта автоматически сгенерированная документация может быть ошибочной и привести не только к разочарованию, но и к ошибке. В производстве.
Рассмотрим следующий сценарий: вас попросили возвращать код состояния ошибки HTTP, если заказ дублируется, но забыли обновить спецификацию OpenAPI с этим новым ответом на статус HTTP. В то время как некоторые фреймворки могут обновлять документацию с новыми полями, ни один из них не может понять, какие ошибки выдает ваш код, этот труд всегда выполняется вручную.
С другой стороны, клиент API делает все правильно, руководствуясь опубликованной вами спецификацией, добавляя заказы с некоторым дублированием, потому что документация не запрещает этого делать. И тут - БУМ, ошибка на производстве -> клиент падает и выдает пользователю уродливое сообщение о неизвестной ошибке.
Этот тип сбоя называется проблемой "контракта", когда взаимодействуют две стороны, у каждой из которых есть код, который работает идеально, просто они работают по разным спецификациям и предположениям. Хотя существуют причудливые и исчерпывающие решения этой проблемы (например, PACT), есть и более простые подходы, которые позволяют решить проблему легко и быстро (ценой покрытия меньших рисков).
Следующий прием основан на использовании библиотек (jest, mocha), которые прослушивают все ответы сети, сравнивают полезную нагрузку с документом OpenAPI и, если обнаружено какое-либо отклонение, делают тест неудачным с описательной ошибкой.
С этим новым оружием в вашем арсенале инструментов и практически без усилий, еще один риск снят. Жаль только, что эти библиотеки не могут ассертировать и входящие запросы, чтобы сообщить вам, что ваши тесты используют API неправильно.
Одна небольшая оговорка и элегантное решение: Эти библиотеки предписывают помещать утверждение в каждый тест - expect(response).toSatisfyApiSpec(), что несколько утомительно и зависит от человеческой дисциплины. Если ваш HTTP-клиент поддерживает плагины/хуки/интерцепторы, вы можете сделать лучше, поместив это утверждение в одно место, которое будет применяться во всех тестах:
Тестируемый код, API выбрасывает новый статус ошибки.
1 2 3 4 5 | |
OpenAPI не документирует HTTP-статус '409', ни один фреймворк не знает, как обновить документацию OpenAPI на основе брошенных исключений
1 2 3 4 5 6 7 8 9 10 | |
Код тестирования
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
Трюк: Если ваш HTTP-клиент поддерживает какой-либо плагин/хук/интерцептор, поместите следующий код в 'beforeAll'. Это покрывает все тесты на несоответствия OpenAPI
1 2 3 4 5 6 7 | |
Еще больше идей¶
- Тестирование готовности и работоспособности маршрутов
- Тестирование сбоев подключения к очереди сообщений
- Тестирование отказов JWT и JWKS
- Тестирование связанных с безопасностью вещей, таких как токены CSRF
- Протестируйте механизм повторных попыток HTTP-клиента (очень просто с помощью nock).
- Протестируйте, что миграция БД прошла успешно и новый код может работать со старым форматом записей
- Тестирование разрывов соединений с БД
Это не просто идеи, это совершенно новое мышление.¶
Приведенные выше примеры - это не просто контрольный список "не забыть", а скорее новый взгляд на то, что могут дать тесты. Современные тесты проверяют не только функции или пользовательские потоки, но и любые риски, которые могут посетить ваше производство.
Это возможно только с помощью компонентных/интеграционных тестов, но никак не с помощью модульных или сквозных тестов. Почему? Потому что, в отличие от модульных, вам нужно, чтобы все части работали вместе (например, файл миграции БД, слой DAL и обработчик ошибок - все вместе).
В отличие от E2E, у вас есть возможность моделировать сценарии внутри процесса, которые требуют доработки и подражания. Компонентные тесты позволяют включать многие производственные движущиеся части на ранних этапах работы. Мне нравится называть это "производственно-ориентированной разработкой".
Ссылки¶
-
Testing the dark scenarios of your Node.js application,
Yoni Goldberg, Raz Luvaton