Развертывание и мониторинг процессов для здорового приложения¶
Мы создаем новый и блестящий Fastify API и хотим выложить его в интернет, чтобы собрать отзывы перед официальным запуском. Когда мы смотрим в интернете, то видим множество вариантов... но что же нам использовать? После этого нам нужно будет понять, как следить за состоянием нашего сервера (ведь мы всегда следим за своими приложениями, верно?).
В этой главе мы рассмотрим основы развертывания монолита с использованием Docker, MongoDB и Fly.io. Мы также рассмотрим ключевые метрики Node.js, как извлечь их из нашего приложения с помощью Prometheus, а затем как легко просмотреть их в Grafana.
Именно этот путь обучения мы рассмотрим в данной главе:
- Тестирование нашего образа Docker для развертывания
- Размещение нашей БД на MongoDB Atlas
- Выбор облачного провайдера
- Развертывание на Fly.io
- Настройка непрерывного развертывания
- Сбор данных о процессах приложения
Технические требования
Как уже упоминалось в предыдущих главах, вам понадобится следующее:
- Работающая установка Node.js 18
- Текстовый редактор для работы с кодом примера
- докер
- HTTP-клиент для тестирования кода, например cURL или Postman
- Аккаунт на GitHub
Все фрагменты в этой главе находятся на GitHub.
Тестирование нашего образа Docker с локальным развертыванием¶
В Главе 6 мы настроили наше приложение для использования с Docker. Это очень важный шаг для нашего приложения TODO List. Теперь пришло время протестировать образ с помощью Docker Compose, чтобы убедиться, что все работает так, как ожидалось.
Давайте повторим наш DockerFile с небольшими изменениями:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Как видите, мы изменили CMD, чтобы напрямую вызывать команду fastify со следующими параметрами:
-a 0.0.0.0— это важно для того, чтобы контейнер мог прослушивать все адреса.--optionsобеспечивает загрузку опций изapp.js.-l infoнастраивает уровень протоколирования.
Теперь мы можем протестировать это развертывание с помощью локального docker-compose, что полезно для проверки того, что все работает хорошо локально, так как это проще для отладки, чем в облаке. В частности, мы собираемся подключить наше приложение к экземпляру MongoDB, запущенному также в Docker.
Сохраним следующий файл под именем docker-compose-test.yml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Давайте пройдемся построчно по содержимому этого файла. Во-первых, мы определяем версию файла docker-compose, так как разные версии имеют разный синтаксис. Во-вторых, мы определяем два сервиса: один из них — mongo, наша база данных, а другой — app, который мы собираем из текущей папки. Обратите внимание, что в определении app мы указываем переменные окружения, которые нужны нашему приложению:
JWT_SECRET, которую следует изменить для обеспечения безопасности вашего приложения.MONGO_URL, которая определяет, как мы подключаемся к нашей базе данных. Обратите внимание, что мы используемmongoв качестве доменного имени — Docker автоматически преобразует его в хост, на котором работает наша MongoDB!
Наконец, важно рассказать о концепции портов в Docker. В файле docker-compose-test.yml мы указываем "3042:3000": мы сопоставляем TCP-порт 3042 хоста с портом 3000 контейнера. Таким образом, теперь мы можем перейти по адресу http://localhost:3042/ и увидеть, что наше приложение запущено.
При такой настройке сохраняйте базу данных в томе данных, чтобы избежать потери данных при удалении контейнера (например, при его обновлении).
Благодаря docker-compose мы можем проверить и протестировать, что наш DockerFile работает так, как ожидалось. Итак, выполните следующее:
1 | |
Docker загрузит базовые образы, соберет наш образ, а затем выполнит наше приложение (если у вас в папке нет package-lock.json, запустите npm i для его создания, иначе docker build выдаст ошибку). Теперь мы можем curl http://localhost:3042/, чтобы убедиться, что все работает так, как ожидалось.
Кластер MongoDB
В документации MongoDB рекомендуется использовать не менее трех узлов MongoDB, поскольку в производстве мы хотим иметь не менее двух копий данных, чтобы выдержать отказ одного узла. В нашем «локальном» развертывании мы используем только одну — это небезопасно, но для наших целей вполне подходит.
Теперь мы хотим перенести нашу установку в облако. Для этого сначала мы воспользуемся MongoDB Atlas для создания кластера MongoDB из трех узлов.
Хостинг нашей БД на MongoDB Atlas¶
Как мы уже писали, самый простой способ создать кластер MongoDB — это использовать MongoDB Atlas, который предоставляет 512 МБ хранилища бесплатно. Чтобы воспользоваться этим способом, следуйте руководству по настройке MongoDB Atlas — хотя мы приводим здесь скриншот, процесс может отличаться.
Первым шагом будет регистрация на MongoDB Atlas. После завершения процесса регистрации и проверки электронной почты вы можете выбрать уровень, на котором будет создана ваша новая база данных. Мы выберем вариант Shared, который является бесплатным. После выбора уровня мы выбираем, где будет расположен наш экземпляр MongoDB. Выбирайте то место, которое находится рядом с вами!
Теперь пришло время добавить механизм безопасности для нашей базы данных. Убедитесь, что вы находитесь на вкладке Quickstart под SECURITY, как показано на Рисунке 10.1. Для этой книги выберите метод аутентификации Имя пользователя и пароль.
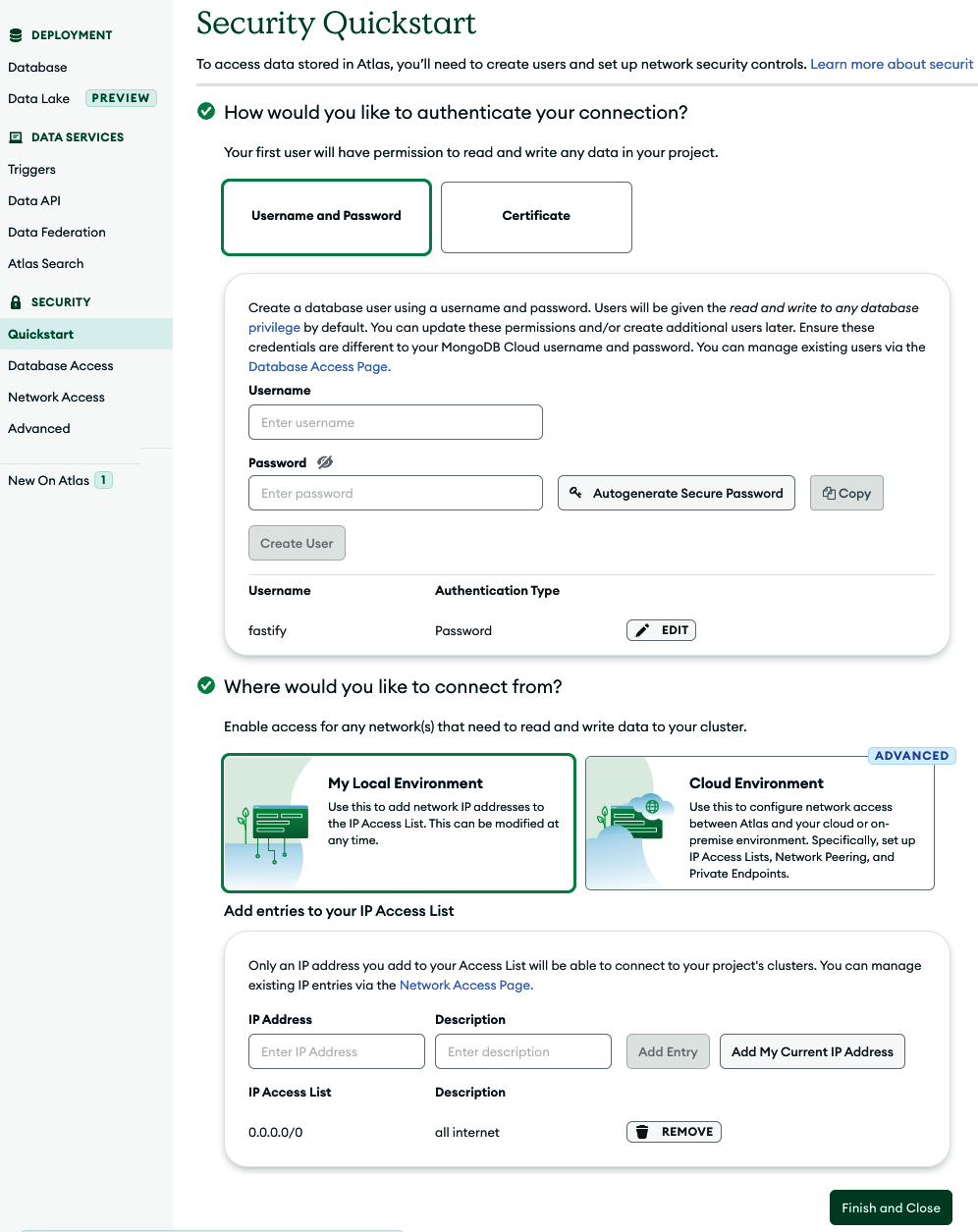
Самая важная настройка для этой книги — разрешить соединения со всех IP-адресов. Это можно сделать в поле IP Address на предыдущем рисунке; введите 0.0.0.0/0, что позволит определить все IP-адреса. Хотя это очень небезопасно, надежного пароля более чем достаточно для простых приложений.
Другие способы подключения
Обратитесь к документации MongoDB Atlas для настройки дополнительных безопасных методов подключения.
Теперь вам нужно скопировать строку подключения к вашей базе данных MongoDB. Это должно быть сделано в опции, похожей на Подключиться к вашей базе данных (мы говорим «похожей», так как не можем назвать точную опцию, потому что она, вероятно, устарела к моменту прочтения).
Теперь мы можем запустить строку подключения в нашем терминале:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Все сработало, как и ожидалось! Теперь мы можем попробовать подключить наше приложение с нашей машины разработки к нашей новой базе данных в облаке следующим образом:
1 2 | |
В качестве альтернативы можно добавить следующее и заменить значение MONGO_URL в файле .env:
1 2 3 | |
Затем в терминале выполните команду npm start.
Поскольку у нас теперь есть облачная база данных, мы можем приступить к развертыванию нашего приложения в облаке!
Выбор облачного провайдера¶
Большинство людей, начинающих использовать новую технологию, задаются вопросом, какой облачный провайдер обеспечит наилучшие условия для развертывания их приложений. В этой книге мы не рассматриваем решения, которые потребуют слишком много усилий, учитывая небольшое свободное пространство.
Вот список провайдеров, на которых стоит обратить внимание:
- Heroku — он начал поддерживать Node.js в 2011 году и на сегодняшний день является одним из самых зрелых и стабильных продуктов.
- Google Cloud Run — основан на Knative и стеке Kubernetes.
- AWS Lambda — это оригинальная «бессерверная» среда исполнения, позволяющая выполнять «функции», которые могут эластично масштабироваться. Каждая функция обрабатывает только один запрос за раз: хотя это упрощает масштабирование и эксплуатацию, приложения с большим объемом ввода-вывода оказываются в невыгодном положении. AWS Lambda основана на Firecracker.
- Vercel — платформа развертывания для фронтенд-команд, основанная на AWS Lambda.
- Fly.io — основана на Firecracker и, как таковая, обеспечивает чрезвычайно быстрый перезапуск процессов и возможность «масштабирования до нуля».
Вы можете найти список других serverless deployments.
Node.js и Fastify выигрывают, когда используются для обслуживания множества параллельных запросов. Это позволяет максимально использовать время простоя в цикле событий для обработки других запросов. Поэтому лучше всего использовать «полные» серверы, которые можно динамически масштабировать в зависимости от нагрузки.
Развертывание на AWS Lambda
Если вы хотите развернуть приложение на AWS Lambda, это возможно использовать. Преимущество нативной разработки в Lambda заключается в том, что вы можете разрабатывать свое приложение так же, как если бы оно было развернуто в стандартном процессе Node.js.
В этой книге мы рассмотрим Fly.io, поскольку он выглядит наиболее инновационным решением и обеспечивает простую автоматизацию непрерывного развертывания.
Развертывание на Fly.io¶
Основной интерфейс Fly.io — это инструмент командной строки под названием flyctl, который мы можем установить следующим образом:
iwr https://fly.io/install.ps1 -useb | iexв Windows PowerShell.curl -L https://fly.io/install.sh | shв Linux и macOS.- Вы также можете использовать
brew install flyctlна macOS.
Зарегистрироваться на Fly.io очень просто: выполните команду flyctl auth signup. Мы рекомендуем подключить ваш аккаунт GitHub, так как он понадобится вам позже.
Теперь мы можем развернуть Fly.io, выполнив команду flyctl launch в текущей рабочей директории (убедитесь, что в ней нет файлов fly.toml) и ответив на следующие вопросы:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Первые вопросы, которые задает flyctl, касаются нашего приложения: какой аккаунт использовать, где его запустить и нужна ли нам база данных PostgreSQL. Затем он создает наш контейнер и развертывает наше приложение на Fly.io.
После этого скрипт пытается развернуть наше приложение до тех пор, пока не потерпит неудачу:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
Как видно из сообщения об ошибке, сервер не может найти переменные окружения JWT_SECRET и MONGO_URL. Давайте добавим их в качестве секретов Fly.io:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
О нет! Он все еще не работает. Что случилось? Давайте откроем файл fly.toml (файл конфигурации Fly.io): там есть строка internal_port = 8080, которая предписывает Fly.io направлять все входящие запросы на порт 8080 нашего контейнера. Однако наше приложение запускается на порту 3000! Давайте изменим строку на internal_port = 3000 и запустим flyctl launch.
Ура! Наше приложение теперь развернуто по адресу https://shy-fog-346.fly.dev/ (замените на свой URL).
В этом разделе мы настроили Fly.io и установили два секрета приложения на Fly.io.
Настройка непрерывного развертывания¶
Мы настраиваем систему непрерывного развертывания, чтобы каждый коммит, добавленный в основную ветку вашего репозитория на GitHub, автоматически разворачивался на Fly.io.
Автоматизация проекта с помощью GitHub Actions
Мы рекомендуем автоматизировать процесс разработки с помощью GitHub Actions. С их помощью можно автоматически запускать автоматизированные тесты, развертывать проект и даже синхронизировать проблемы с другими программами управления.
Для начала давайте создадим репозиторий на GitHub, клонируем его локально и загрузим туда наш код! Чтобы загрузить наш код на GitHub, выполним в терминале команды git clone, git add, git commit и git push.
Использование Git и GitHub
Если вы не знакомы с Git и GitHub, мы рекомендуем вам следовать руководству GitImmersion tutorial, а также https://docs.github.com/en/get-started/quickstart/create-a-repo, чтобы создать репозиторий на GitHub, клонировать его и развернуть наше приложение.
Чтобы развертывание на Fly.io происходило автоматически, мы должны установить и настроить клиент flyctl. Нам нужно будет аутентифицировать наш GitHub Action на Fly.io, и для этого нам нужен токен авторизации Fly.io. Его можно сгенерировать, выполнив команду fly auth token в терминале.
После этого скопируйте это значение и откройте наш репозиторий GitHub. Внутри Settings | Secrets | Actions откройте New Repository Secret. Затем задайте FLY_API_TOKEN в качестве имени и наш токен в качестве значения, и нажмите на Add secret.
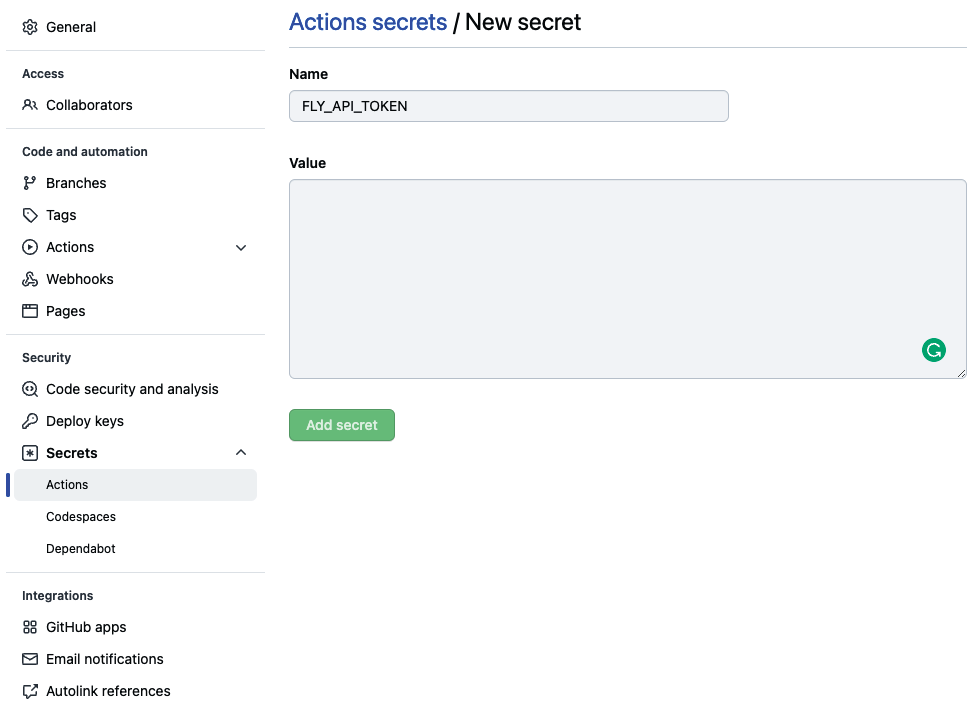
После настройки нашего секрета пришло время использовать GitHub Actions для автоматического развертывания нашего приложения. Для этого в нашей рабочей директории создайте файл .github/workflows/fly.yml со следующим содержимым:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Этот GitHub Action использует действие setup-flyctl для настройки клиента Fly.io, а затем использует flyctl для развертывания нашего кода. Чтобы выполнить развертывание, ему нужна переменная окружения FLY_API_TOKEN, которую мы задаем в секции env определения действия (взяв значение из секрета, который мы ранее настроили в настройках репозитория).
Затем мы добавляем этот файл в Git-репозиторий, фиксируем его и отправляем на выполнение. В результате действие должно запуститься и развернуть наше приложение:
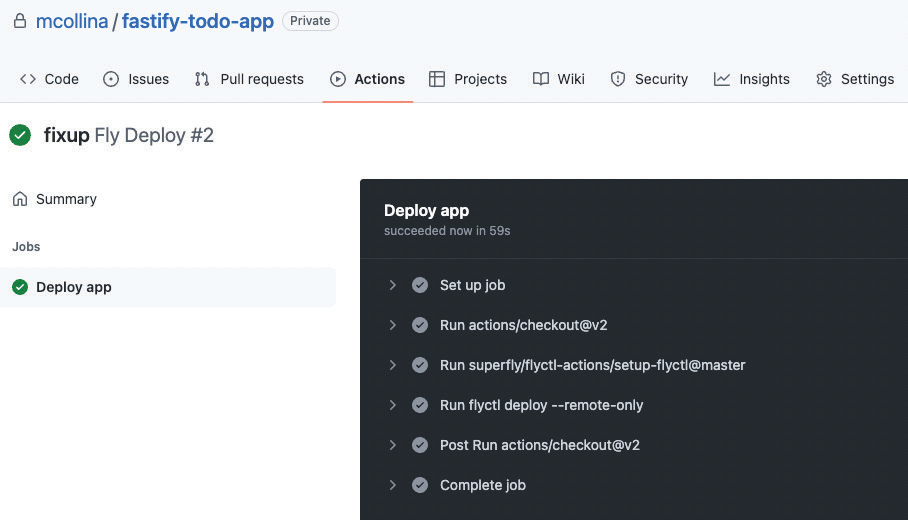
Далее мы хотим настроить мониторинг нашего развернутого приложения, чтобы держать его под контролем!
Сбор данных о процессах приложения¶
Отрывок из выступления «Мой процесс Node.js горит»
В 10 утра в «черную пятницу» у вас звонит телефон: новое JS-приложение, которое вы развернули, подверглось слишком большой нагрузке, и сайт упал! Ваш работодатель теряет возможности для продаж... Ваш работодатель теряет деньги! Но вы не теряете самообладания. Вы заходите в облако провайдера и изменяете настройки автомасштабирования. Теперь развертывание может справиться со скачком нагрузки, но с использованием в четыре раза большего количества серверов, что в четыре раза дороже. На следующий день вы пытаетесь проанализировать, что произошло, и начинаете оптимизировать свое приложение, чтобы подготовиться к будущим скачкам нагрузки».
Этот полный доклад был сделан Маттео Коллиной на JSConf Asia 2018.
Основная причина, по которой мы хотим собирать метрики нашего работающего процесса Node.js, — это возможность диагностировать и отлаживать проблемы спустя часы, дни или даже недели после их возникновения. Поток диагностики производственных проблем описан на следующем рисунке:
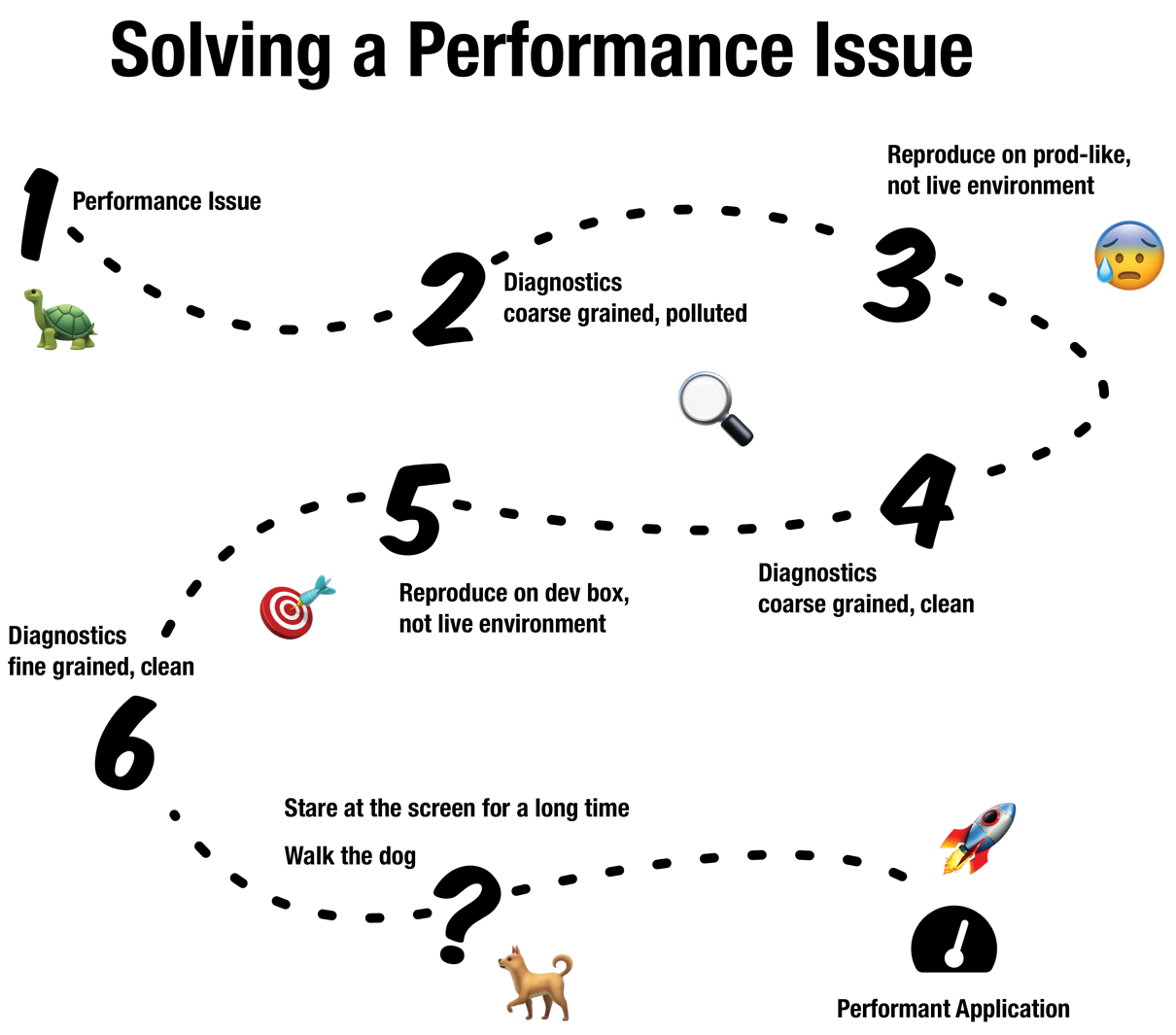
Нам нужно собрать данные, чтобы понять, что произошло, и воспроизвести проблему в неживой среде — иначе мы не сможем понять, устранили ли мы проблему! После этого мы используем более тонкие инструменты для локального воспроизведения и разработки исправления. Какие инструменты мы будем использовать? Мы рассмотрим их в главе 13.
Сбор данных о процессе приложения с помощью Prometheus¶
Prometheus — это лучшее решение с открытым исходным кодом для сбора и хранения данных временных рядов, которое обычно используется для реализации систем мониторинга в приложениях. Очень удобно иметь статистику работы системы, даже в условиях сбоя. В Prometheus также есть компонент менеджера оповещений, который мы можем использовать для получения обновлений в случае сбоев.
Архитектура Prometheus разделена на различные компоненты: в ее основе лежит сервер Prometheus, который получает метрики от каждой цели через точные интервалы времени (несколько раз в минуту). Для короткоживущих заданий существует Pushgateway, который позволяет Prometheus получать эти метрики. Клиенты визуализации — такие как Grafana — запрашивают Prometheus с помощью PromQL.
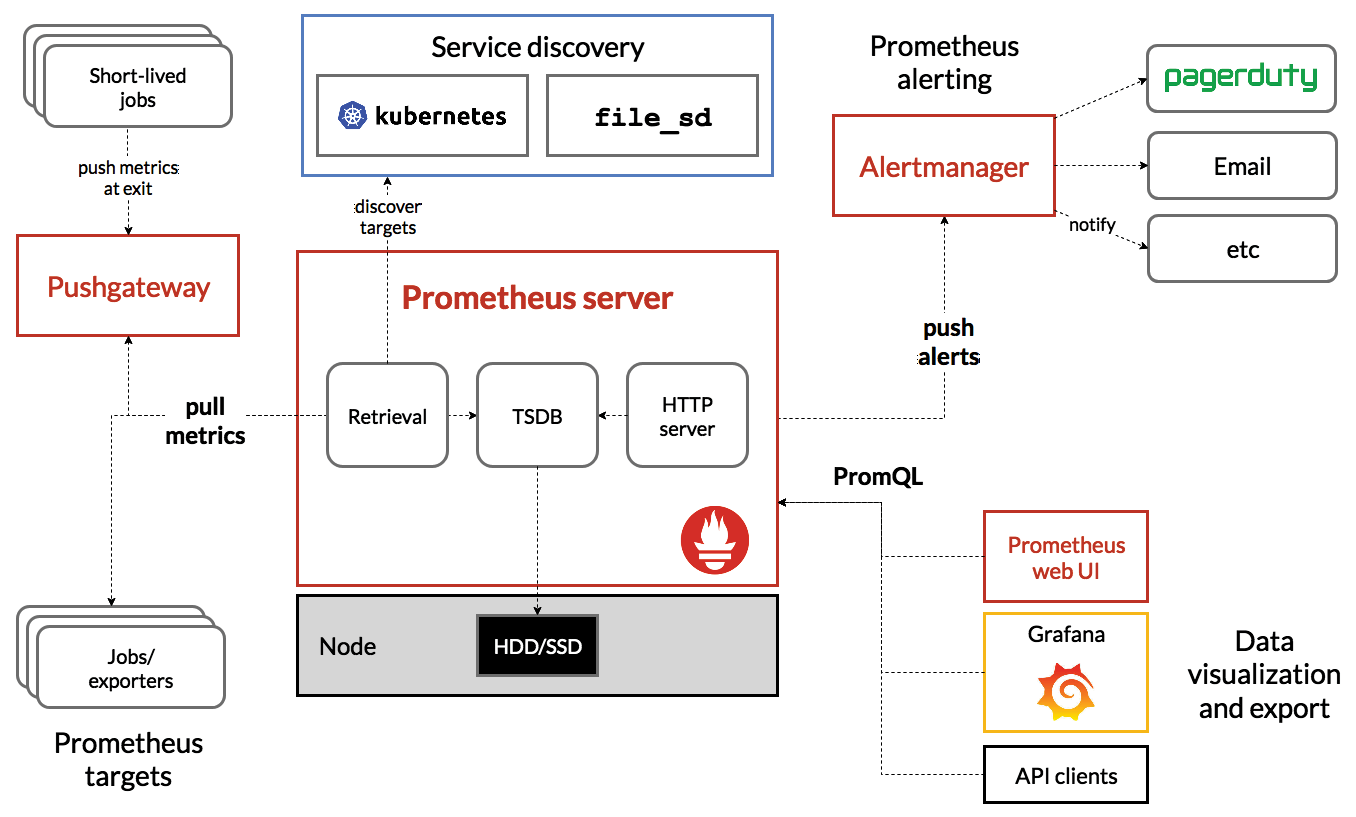
Эта книга не посвящена Prometheus и всем его возможностям; однако мы расскажем о том, как настроить наше приложение Fastify на предоставление данных для сбора Prometheus. Мы также расскажем о встроенной поддержке Fly.io для Prometheus и о возможностях сбора данных.
Prometheus
За дополнительной информацией о Prometheus обращайтесь к документации Prometheus.
Основной библиотекой Node.js, которая создает метрики в нужном формате для извлечения Prometheus, является prom-client. fastify- metrics использует ее и интегрирует с Fastify.
Prometheus и Fly.io рекомендуют выставлять метрики на TCP-порт, отличный от порта нашего основного сервиса, который обычно равен 9001. Поэтому мы хотим собирать метрики для нашего основного процесса и запустить отдельный сервер Fastify для передачи этих метрик скребку. Поэтому мы создаем файл plugins/metrics.js со следующим содержимым:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
Затем нам нужно настроить Fly.io на получение наших пользовательских метрик в своем решении для мониторинга. Таким образом, мы добавляем следующее в fly.toml:
1 2 3 | |
Далее мы запускаем в терминале нашу обычную тройку команд: git add ., git commit и git push. После того как GitHub Action развернет наш код, мы можем протестировать его, используя следующее:
1 2 3 4 5 6 7 8 9 10 | |
Команда curl проверяет, что Fly.io теперь следит за нашим приложением — в частности, она проверяет количество активных хендлов (сокетов и т. д.) в Node.js. Команда использует схему авторизации с использованием токена на предъявителя (т.е. заголовок Authorization), поэтому нам понадобится токен авторизации Fly.io, который мы сгенерировали ранее. Если вы не скопировали токен авторизации, вы можете получить его с помощью команды fly auth token. При выполнении этого кода не забудьте также обновить название приложения на свое.
Grafana будет использовать эту конечную точку для получения данных для своих визуализаций.
Исследование метрик с помощью Grafana¶
В этой книге мы будем использовать Grafana Cloud, хостинговую версию проекта Grafana с открытым исходным кодом. Чтобы начать работу, перейдите по адресу https://grafana.com/ и зарегистрируйте новый бесплатный аккаунт. В итоге вы окажетесь на следующем экране:
Нажмите на Подключить данные (или в меню нажмите на Подключения), а затем выполните поиск Prometheus:
Далее нажмите на Источник данных Prometheus, затем Создать источник данных Prometheus:
Теперь мы можем настроить наш источник данных Prometheus. Мы используем подход, аналогичный команде curl в предыдущем разделе: мы должны авторизовать Grafana для получения данных с Fly.io. Для этого мы задаем в заголовке Authorization значение Bearer TOKEN, где TOKEN — это вывод fly auth token. На следующем рисунке показана окончательная конфигурация.
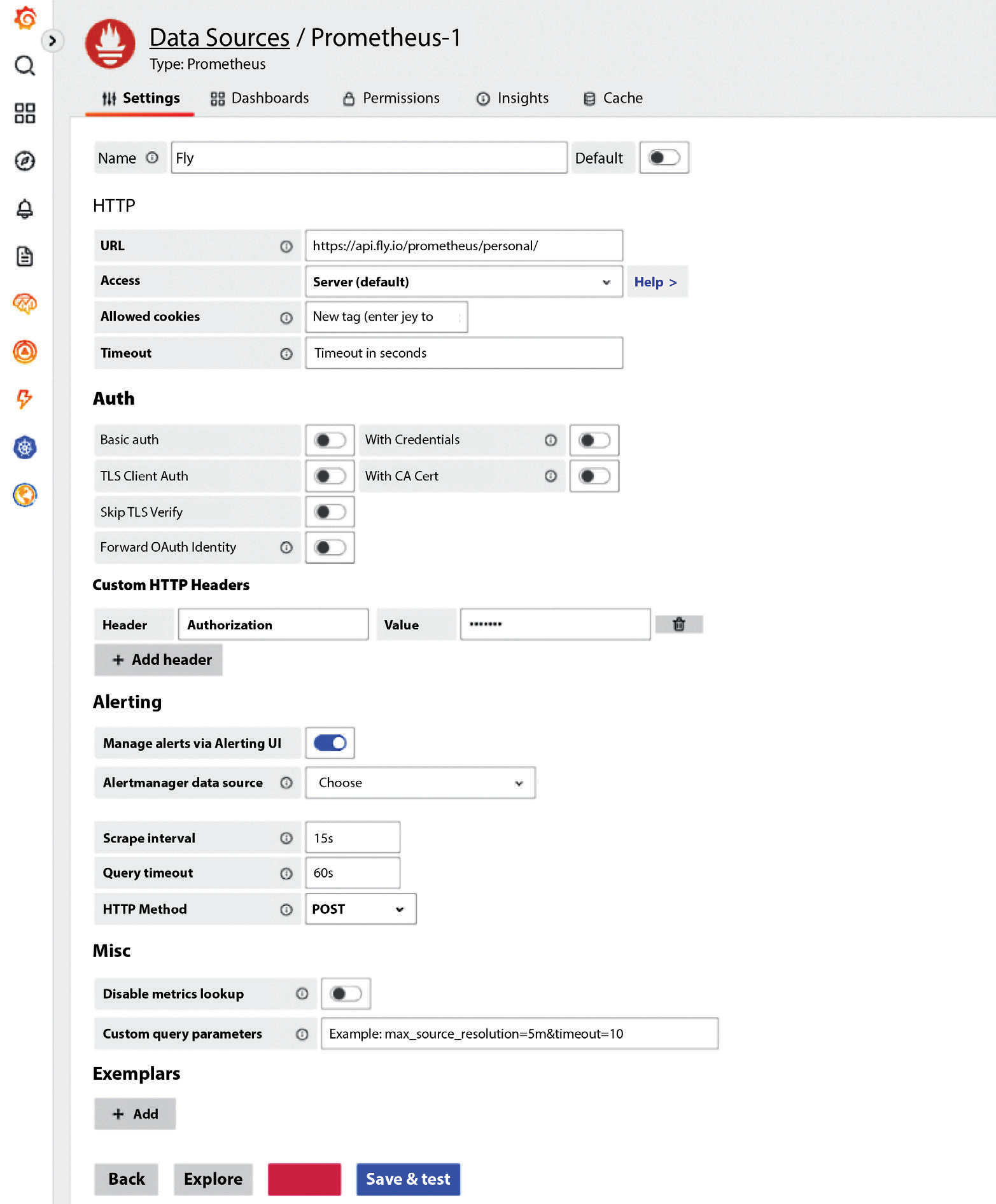
Grafana и Fly.io
Вы можете найти дополнительную информацию о [том, как Fly.io может интегрироваться с Grafana] (https://fly.io/docs/reference/metrics/#grafana).
Теперь нажмите Save & test, затем Explore. В следующем окне выберите fly_instance_memory_mem_total в качестве метрики, примените app = shy-fog-346 в качестве метки (используйте собственное имя приложения) и нажмите Run query. Окончательная настройка будет выглядеть следующим образом:
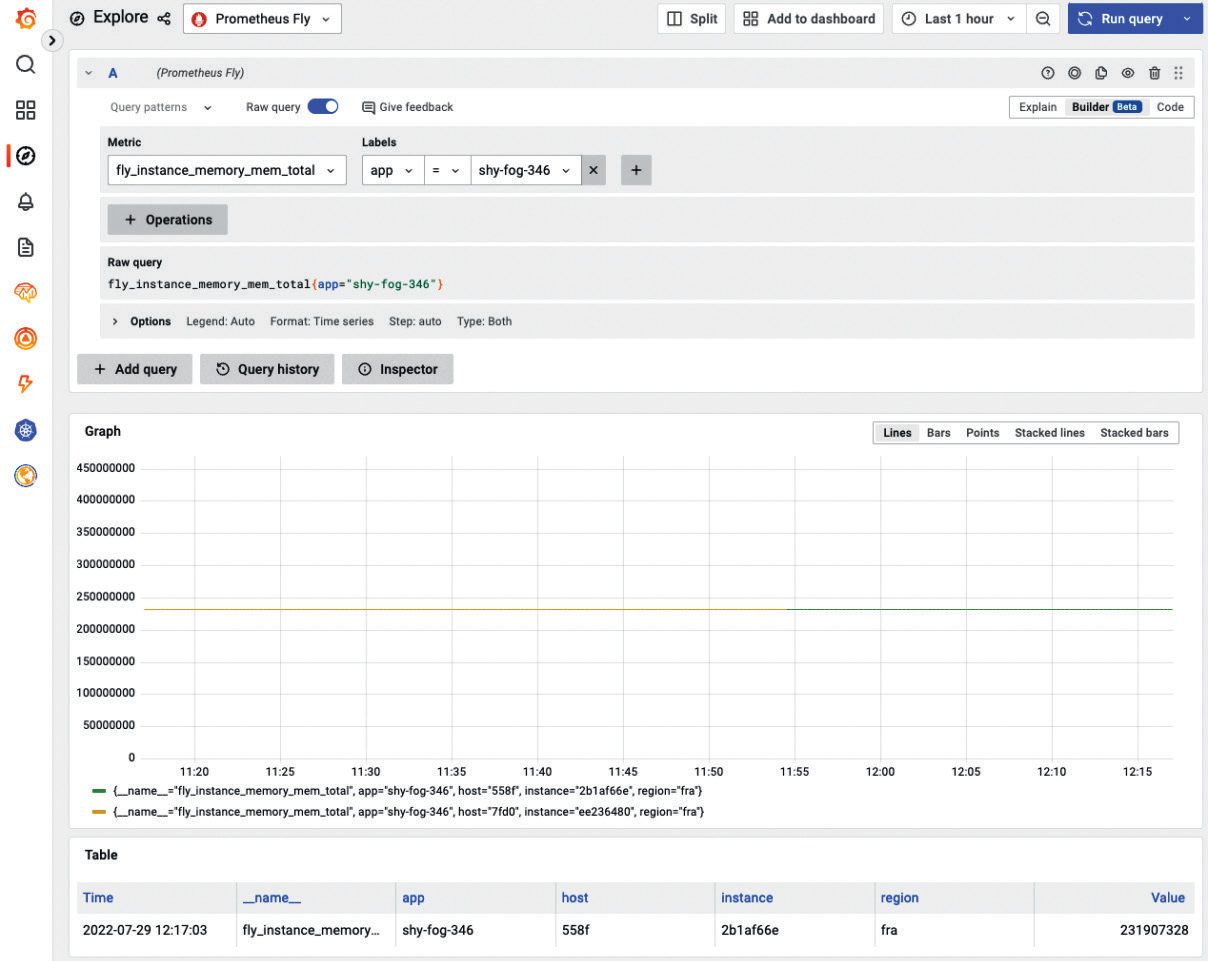
Здесь мы видим, как Fly.io следит за памятью нашего приложения.
Модуль fastify-metrics предоставляет несколько интересных метрик, касающихся Fastify:
http_request_duration_seconds_count— общее количество HTTP-запросов в интервалеhttp_request_summary_seconds— длительность запроса, разделенная на проценты
Prom-client предоставляет метрики для экземпляра Node.js. Вы можете обратиться к https://github.com/siimon/prom-client/tree/721829cc593bb7da28ae009985caeeacb4b59e05/lib/metrics за полным списком доступных метрик, но я рекомендую вам построить график следующих:
nodejs_event_loop_lag_p99_seconds— для отслеживания того, насыщается ли наш цикл событий и нужно ли дальше оптимизировать наше приложениеnodejs_heap_space_used_bytes— чтобы отслеживать, сколько памяти использует наше приложение, и выявлять проблемы с памятью на ранней стадии.
В качестве другого примера мы можем построить график максимальной задержки по всем маршрутам для каждого экземпляра нашего приложения:
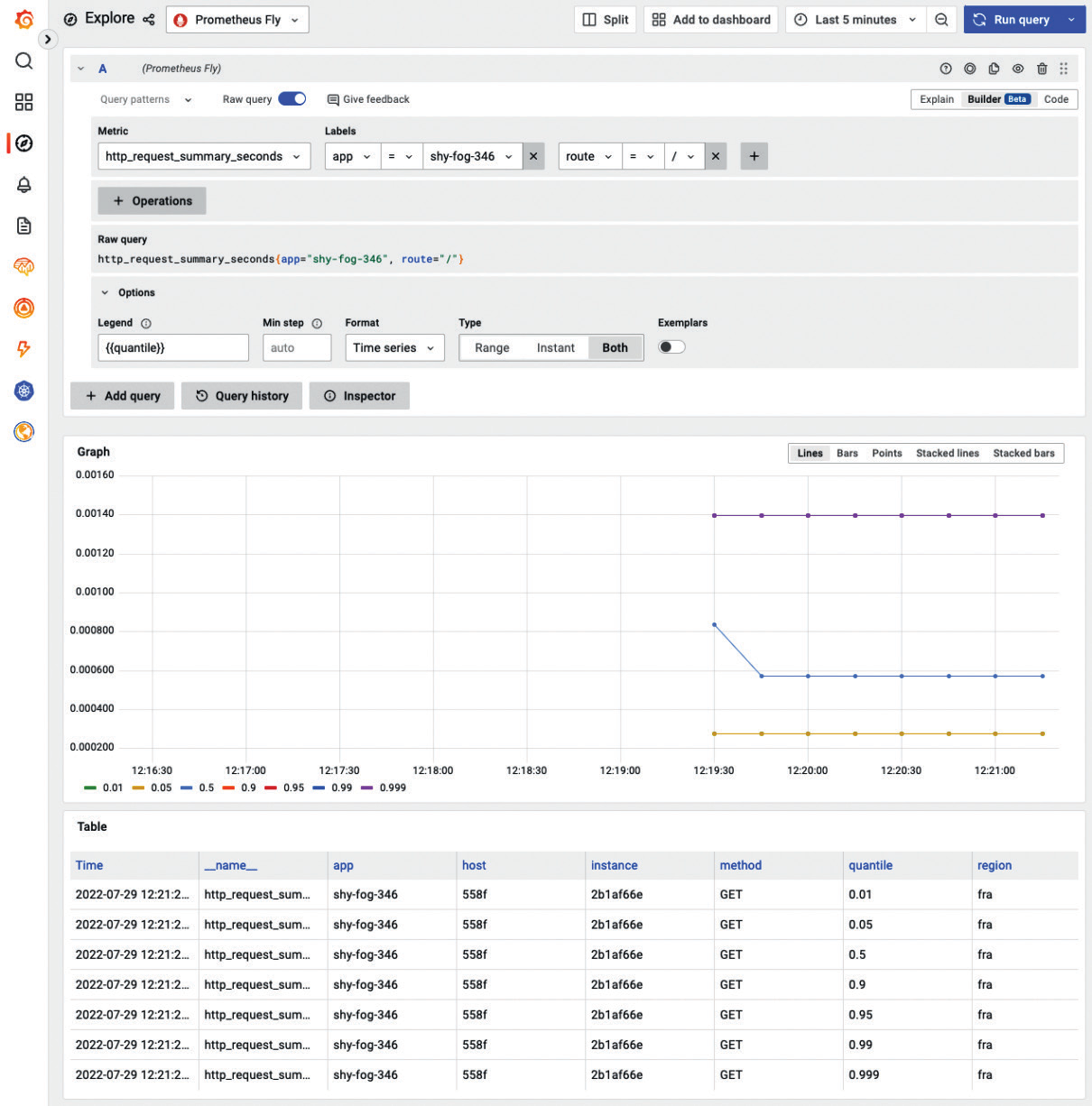
На предыдущей диаграмме показана задержка всех маршрутов нашего сервера при различных квантилях. Нас интересуют квантили 0,95 и 0,99, поскольку они учитывают большинство запросов, исключая при этом провалы. Это полезно для того, чтобы понять, как работает наше приложение для большинства пользователей.
Квантиль или перцентиль
В статистике и теории вероятностей квантили — это точки среза, делящие диапазон распределения вероятностей на непрерывные интервалы с равными вероятностями, или делящие наблюдения в выборке таким же образом. Количество квантилей на один меньше, чем количество созданных групп. Общие квантили имеют специальные названия, например, квартили (четыре группы), децили (десять групп) и перцентили (100 групп). Созданные группы называются половинами, третями, четвертями и т. д., хотя иногда термины для квантилей используются для созданных групп, а не для точек отсечения."_ — https:// en.wikipedia.org/wiki/Quantile.
Мы узнали, как интегрировать Fly.io с Grafana Cloud, и теперь у нас есть мощный сайт мониторинга, который мы можем настроить по своему вкусу. В качестве упражнения мы рекомендуем изучить все метрики, доступные в Grafana, и создать полноценный дашборд!
Grafana
Чтобы узнать больше о Grafana, прочитайте статью Learn Grafana 7.0, написанную Эриком Салитуро.
Резюме
В этой главе мы развернули наше приложение Fastify на Fly.io с базой данных, размещенной в MongoDB Atlas. Затем мы добавили мониторинг с помощью экземпляра Prometheus, размещенного на Fly.io. Наконец, мы подключили Prometheus к Grafana Cloud.
В следующей главе мы расскажем о том, как настроить ведение журналов в приложении Fastify для получения читаемых, проверяемых и полезных журналов.