Разработка GraphQL API¶
GraphQL набирает популярность, и с каждым днем все больше сервисов раскрывают свои API с помощью этого языка запросов. Интерфейс GQL API поможет вашим потребителям API получить минимальный набор необходимых им данных, пользуясь интуитивно понятной и всегда обновляемой документацией. GraphQL является первоклассным гражданином в экосистеме Fastify.
Давайте узнаем, как добавить обработчики GraphQL с помощью специального плагина, избегая распространенных подводных камней и используя преимущества особой архитектуры Fastify.
Вот путь обучения, который мы пройдем в этой главе:
- Что такое GraphQL?
- Написание схемы GQL
- Как сделать схему GQL живой?
- Как повысить производительность резолвера?
- Управление ошибками GQL
Технические требования
Чтобы успешно завершить эту главу, вам потребуется:
- Рабочая установка Node.js 18
- VS Code IDE
- Рабочая командная оболочка
Все сниппеты в этой главе находятся на GitHub.
Что такое GraphQL?¶
GraphQL — это новый язык, который изменил то, как веб-сервер раскрывает данные и как клиент их потребляет. Учитывая структуру данных нашего приложения, мы можем представить каждый источник данных в виде графа, состоящего из узлов (объектов) и ребер (отношений), соединяющих их.
Вот краткий пример GraphQL-запроса, который отображает семью и ее членов:
1 2 3 4 5 6 7 8 9 10 11 | |
Прочитав наш первый GraphQL-запрос, мы можем сразу понять иерархию отношений. Сущность Family имеет множество сущностей Person в качестве свойства массива members. Каждый элемент members может иметь несколько сущностей Person в качестве friends. Обычно строку GQL-запроса называют GQL-документом.
JSON-ответ на наш GQL-запрос может выглядеть следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Видя предыдущий пример, вы можете предположить, что если бы вы хотели получить те же данные, используя архитектуру REST API, то вам пришлось бы выполнить множество HTTP-вызовов, например:
- Вызов конечной точки
GET /family/5для получения членов семьи - Вызов
GET /person/idдля каждого члена семьи, чтобы получить информацию о его друзьях.
Такая простота взаимодействия гарантирована, поскольку GraphQL — это декларативный, интуитивно понятный и гибкий язык, позволяющий сосредоточиться на форме данных. Его задача — разработать структурированную и продуктивную среду для упрощения получения API клиентом.
Для достижения своих целей он имеет множество принципов проектирования:
- Ориентированность на продукт: Язык строится вокруг требований потребителей и визуализации данных.
- Иерархичность: Запрос имеет иерархическую форму, которая определяет структуру данных ответа
- Стронг-типирование: Сервер определяет систему типов приложений, используемую для проверки каждого запроса и документирования результатов ответа
- Определенный клиентом ответ: Клиент знает возможности сервера и то, какие из них ему разрешено использовать
- Интроспективный: Система типов сервиса GraphQL может быть запрошена с помощью самого языка GraphQL для создания мощных инструментов.
Эти принципы лежат в основе спецификации GraphQL, и подробнее о них вы можете узнать на сайте.
Но что нужно для реализации спецификации GraphQL? Давайте выясним это в следующем разделе.
Как Fastify поддерживает GraphQL?¶
GraphQL описывает язык, но мы должны реализовать спецификацию, чтобы поддерживать его грамматику. Итак, мы рассмотрим, как реализовать GraphQL в Fastify, пока изучаем спецификацию. Мы напишем исходный код для поддержки примера GQL, который мы рассматривали в предыдущем разделе.
Для начала нам нужно определить компоненты. На следующей диаграмме показаны архитектурные концепции, поддерживающие GraphQL:
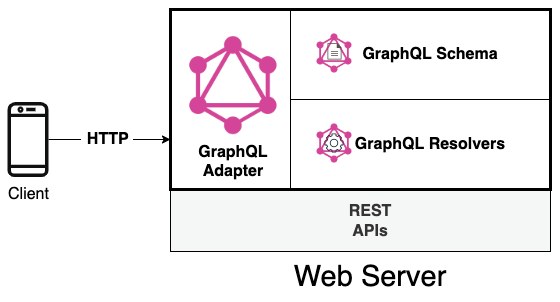
На рисунке 14.1 показано несколько основных понятий о GraphQL:
- Любой клиент может выполнить документ GraphQL, выполнив HTTP-запрос к веб-серверу.
- Веб-сервер понимает GQL-запрос, используя GraphQL-адаптер, который взаимодействует с определением GraphQL-схемы и GraphQL-резольверами. Все эти понятия будут рассмотрены далее в разделе Как сделать живую схему GQL?.
- Веб-сервер может без проблем открывать несколько REST API помимо GQL.
Для реализации нашего первого GraphQL-сервера мы будем следовать следующему прямолинейному процессу:
- Определите схему GQL.
- Напишите простой сервер Fastify.
- Добавьте плагин
mercuriusи адаптер GraphQL, разработанный для Fastify, к установке Fastify. - Реализуйте GQL-резольверы.
Итак, давайте начнем работать над синтаксисом GQL, чтобы написать нашу первую схему.
Написание GQL-схемы¶
Мы должны написать схему GQL, используя его систему типов. Если мы сначала подумаем о наших данных, нам будет проще их реализовать. Давайте попробуем преобразовать следующую диаграмму в схему:

Отношение данных на рисунке 14.2 описывает сущности и отношения между ними:
- У семьи есть несколько членов.
- У человека может быть множество друзей, которые являются другими членами семьи.
Таким образом, мы можем представить эти сущности в виде объектных типов, написав следующий язык определения схем (SDL):
1 2 3 4 5 6 7 8 9 10 11 12 | |
Синтаксис для определения сущности GQL легко читается. Мы определили два типа. Каждый тип имеет имя в PascalCase и список полей, окруженных фигурными скобками.
Каждое поле определяется словами <имя поля>: <тип поля>. Тип поля определяет тип значения поля ответа. Возможно, в предыдущем блоке кода вы увидели восклицательный знак в конце. Это GQL-модификатор типа, который объявляет поле не нулевым. Возможные варианты синтаксиса:
<имя поля>: <тип поля>!: Не нулируемое поле. Клиент всегда должен ожидать значение ответа.<имя поля>: [<тип поля>]: Поле возвращает обнуляемый массив с обнуляемыми элементами.<имя поля>: [<тип поля>!]: Возвращаемый массив является обнуляемым, но в нем не будет обнуляемых элементов.<Имя поля>: [<тип поля>!]!: Определяет не нуллируемый массив без элементовnull. В результате массив может оказаться пустым.
Тип поля может быть другим типом, определенным самостоятельно, как мы сделали для типа family, или может быть скаляром. Скаляр представляет собой примитивное значение, и по умолчанию каждый адаптер GQL реализует:
Int: Представляет знаковое 32-битное число.Float: Представляет значения с плавающей точкой.String: Текстовое значение данных, представленное в виде символов UTF-8.Boolean: Истинное или ложное значение.ID: Представляет собой уникальный идентификатор (UID). Принимает числовые значения, но всегда сериализуется как строка.
Спецификация позволяет определять дополнительные скаляры, такие как Date или DateTime.
Теперь мы написали наши объектные типы GQL, но как использовать их для чтения и редактирования? Давайте узнаем это в следующем разделе.
Определение операций GQL¶
Документ GQL может содержать различные операции:
query: Действие только для чтенияmutation: Операция записи и чтения.subscription: Постоянное соединение с запросом, которое извлекает данные в ответ на события.
Эти операции должны быть определены в схеме GQL, чтобы их мог использовать клиент. Давайте улучшим наш SDL, добавив следующий код:
1 2 3 4 5 6 7 8 9 | |
Предыдущий фрагмент кода добавляет по одной операции для каждого типа, поддерживаемого спецификацией GQL. Как вы можете прочитать, мы использовали синтаксис типа <операция>. Эти типы называются корневыми типами операций. Каждое поле в определениях этих специальных типов будет соответствовать резольверу, который реализует нашу бизнес-логику.
В дополнение к тому, что мы узнали из вводного раздела Написание схемы GQL об определении type, мы видим, что некоторые поля имеют входные параметры: family(id: ID!): Family. Фактически, синтаксис такой же, как мы обсуждали ранее, но есть один дополнительный аргумент, который мы можем объявить как функцию JavaScript: <имя поля>(<аргументы поля>): <тип поля>.
Как мы уже писали в нашем примере SDL, аргументы поля changeNickName могут быть либо списком полей. Когда мы должны иметь дело с большим количеством параметров, мы можем использовать тип input. Объект типа input работает как объект type, но может использоваться только в качестве пользовательского ввода. Он полезен, когда нам нужно объявить более сложные объекты ввода. Давайте добавим в нашу схему GQL еще одну мутацию, которая принимает тип input:
1 2 3 4 5 6 7 8 | |
Мы определили GQL-тип input NewNickName, который похож на тип объекта Person, но не содержит полей, которые пользователь не может задать.
Отлично! Мы написали схему GQL нашего приложения. Вы увидели все основные вещи, необходимые для определения схем GQL. Прежде чем углубляться в спецификацию GQL, изучая другие ключевые слова и допустимые синтаксисы, мы должны консолидировать наше приложение, реализовав бизнес-логику. Пришло время писать код!
Как сделать живую схему GQL?¶
В разделе Writing the GQL Schema мы написали GQL-схему приложения. Теперь нам нужно инициализировать новый проект npm. Для простоты и чтобы сосредоточиться только на логике GQL, мы можем создать его, выполнив следующий код:
1 2 3 4 | |
Мы готовы создать наш первый файл, gql-schema.js. Здесь мы можем просто скопировать схему GQL, которую мы написали в предыдущем разделе:
1 2 3 | |
Прежде чем продолжить, стоит упомянуть, что существует два разных способа определения схемы GQL в Node.js:
- Schema-first: Схема GQL — это строка, написанная в соответствии со спецификацией GQL.
- Code-first: Схема GQL генерируется внешним инструментом, например, модулем
graphql npm.
В этой главе мы будем следовать реализации schema-first, поскольку она является наиболее общей и позволяет получить четкое представление о схеме без запуска приложения для ее генерации во время выполнения.
Пришло время загрузить схему, которую мы написали в разделе Writing the GQL schema, и запустить GQL-сервер. Рассмотрим, как это сделать, в следующем разделе.
Запуск GQL-сервера¶
Чтобы создать GQL-сервер, нам нужно создать экземпляр Fastify и зарегистрировать плагин mercurius, как мы узнали на протяжении всей этой книги. Создайте новый файл app.js:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Вы должны быть в состоянии прочитать этот небольшой фрагмент кода Fastify. Мы импортировали адаптер GQL и схему в строке [1]. В строке [2] мы объявили пустой объект resolvers и зарегистрировали плагин mercurius на сервере приложений. Если мы запустим приложение под управлением node app.js, оно запустится корректно и будет готово принять GQL-запрос.
Для проверки мы можем запустить команду curl, например, так:
1 2 3 4 | |
Команда вернет пустой ответ:
1 2 3 4 5 | |
Давайте сделаем шаг назад и проанализируем происходящее:
- Регистрация плагина
mercuriusприводит к появлению конечной точки/graphql, готовой принимать запросы GQL. - Поскольку опция
resolversявляется пустым объектом, все операции приложения не выполняют никакой бизнес-логики, и на выходе получается значениеnullпо умолчанию. - Каждый клиент может выполнить HTTP-запрос к обслуживаемой конечной точке GQL. Формат HTTP-запроса также определяется спецификацией GQL.
К отправке GQL-запроса по HTTP предъявляется очень мало требований:
- Должен быть параметр
query, который содержит строку GQL-запроса. - Можно определить параметр
variables, который будет выполнять роль специального заполнителя в строке GQL-запроса. Он должен быть обычным JSON-объектом. - HTTP-запрос должен быть вызовом метода GET или POST. В первом случае параметры должны быть переданы как параметр строки запроса. Во втором случае полезная нагрузка запроса должна представлять собой объект JSON, как это было в нашем примере с
curl.
Если вы хотите узнать все подробности о спецификации, вы можете глубоко погрузиться в эту тему в официальной документации. Mercurius поддерживает все спецификации, так что вам не нужно беспокоиться об этом!
Параметр OperationName
В качестве опции вы можете определить более одного типа корневой операции в одном GQL-запросе. В этом случае в HTTP-запрос необходимо добавить дополнительный параметр operationName. Он будет выбирать операцию для выполнения. Примером может служить включение в полезную нагрузку GQL-запроса операций mutation и query, а затем указание, какая из них должна быть выполнена. Этот способ часто используется на этапе разработки, и вы увидите его в действии в следующем разделе.
Мы запустили наш GQL-сервер, но нам нужно добавить нашу бизнес-логику, поэтому пришло время реализовать некоторые GQL-резольверы в следующем разделе.
Реализация нашего первого резольвера GQL-запросов¶
GQL-резольверы реализуют бизнес-логику нашего приложения. Функцию резольвера можно прикрепить почти к каждой возможности схемы GQL, за исключением типа корневых операций. Вкратце перечислим все компоненты системы типов, которые могут иметь пользовательскую функцию resolver:
- Объекты типа
- Поля типа
- Скаляры
- Перечисления
- Директивы и союзы
Мы не будем подробно обсуждать эти темы, поскольку они выходят за рамки данной книги.
Как мы уже говорили в разделе Определение операций GQL, операция определяется как поле корневого типа операции, поэтому реализация запроса family(id: ID!) будет похожа на реализацию резольвера поля.
Прежде чем мы продолжим наш путь к реализации резольверов, нам понадобится база данных для подключения. Чтобы сосредоточиться на аспекте GQL в этой главе, мы применим некоторые быстрые клавиши, чтобы создать максимально быструю конфигурацию для работы с GQL. Итак, давайте добавим в наш файл app.js экземпляр SQLite in-memory, который будет заполняться имитируемыми данными при каждом перезапуске. Мы должны выполнить команду npm install fastify-sqlite, а затем отредактировать наш файл приложения, как показано ниже:
1 2 3 4 5 6 7 8 9 | |
Этот фрагмент кода добавляет плагин fastify-sqlite к нашему приложению Fastify. По умолчанию он подключает наше приложение к экземпляру SQLite в памяти. Модуль добавляет удобную утилиту migrate, которая позволяет нам запускать все файлы .sql, включенные в директорию migrations/, которую мы должны создать. В папке migrations/ мы можем создать новый файл 001-init.sql, содержащий нашу схему SQL, которая воссоздает таблицы и отношения, показанные на Рисунке 14.2. Кроме того, сценарий должен добавить некоторые имитированные данные, чтобы ускорить создание прототипа. Вы можете просто скопировать и вставить его из репозитория книги.
Проект на GQL готов, и теперь мы можем реализовать бизнес-логику. Нам нужно настроить переменную resolvers, которую мы написали в разделе Запуск GQL-сервера. Конфигурация относительно проста и выглядит следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Если мы попробуем проанализировать реализацию запроса family(id: ID!), то сразу поймем структуру параметра resolvers. Ключ Query представляет корневой тип операции запроса, и все его ключи должны совпадать с записью в соответствующем корневом типе операции, определенном в схеме GQL.
Контроль соответствия
Во время запуска Fastify, если мы добавим функцию resolver в объект конфигурации Query, не объявив ее в нашей схеме GQL, Mercurius выдаст ошибку.
Объект resolvers сообщает нам, что существует запрос с именем family. Каждый раз, когда поступает GQL-запрос, GQL-адаптер должен выполнить нашу функцию familyFunc. Резольвер может быть как асинхронной, так и синхронной функцией, принимающей четыре параметра:
parent— это возвращаемое значение предыдущего резольвера. Вы должны знать, что для резолверов запроса и мутации это всегда пустой объект, потому что предыдущих резолверов не существует. Не волнуйтесь, если это еще не ясно — через некоторое время мы рассмотрим пример.args— это параметр JSON, содержащий все входные параметры запроса. В нашем примере запрос family определяет обязательный входной параметрid. Таким образом,args.idбудет содержать входные данные пользователя.context— это общий объект для всех резолверов. Mercurius создает его для каждого запроса и выполняет его с ключомapp, связывая приложение Fastify и объектreply.- Аргумент
infoпредставляет собой узел GraphQL и его состояние выполнения. Это низкоуровневый объект, и вам редко придется иметь с ним дело.
Теперь мы можем отправить запрос на наш сервер, но я согласен с тем, что писать команду curl очень громоздко. Итак, давайте рассмотрим еще одну классную возможность Mercurius. Если мы немного подправим конфигурацию, то сможем открыть отличную утилиту:
1 2 3 4 5 | |
Включение опции graphiql включит клиент GraphQL (обратите внимание на i в graphiql). Запустив приложение node app.js и перейдя в браузере по адресу http://127.0.0.1:3000/graphiql, вы увидите следующий интерфейс:
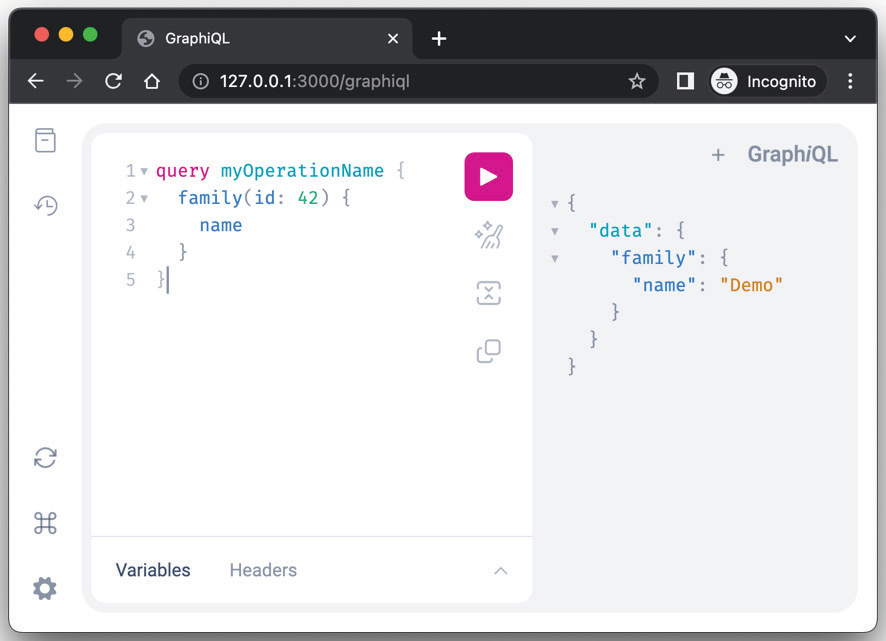
До сих пор мы писали декларацию схемы GQL, но теперь нам нужно написать строку запроса GQL, чтобы запросить сервер. Интерфейс graphiql позволяет нам играть с нашим сервером GraphQL. Он извлекает схему GQL и предоставляет нам автозаполнение и другие утилиты для более удобного написания GQL-документов.
Так, мы можем использовать его для выполнения простого запроса family (id:42) { name }, как показано на Рисунке 14.3. Синтаксис направлен на выполнение запроса family с аргументом id, установленным в 42. Между фигурными скобками мы должны перечислить все поля типа объекта, которые мы хотим прочитать с сервера. Таким образом, мы вынуждены выбирать только интересующие нас данные, не расходуя ресурсы и сохраняя полезную нагрузку как можно более легкой.
Запустив запрос, нажав кнопку play в центре экрана, мы запустим обращение к серверу, который покажет ответ в правой части экрана. Вы можете заметить, что поле JSON data содержит полезную нагрузку ответа. Эта структура также определена спецификацией.
Если мы перейдем к логам сервера, то увидим сообщение в логе TODO my business logic. Это означает, что преобразователь был успешно выполнен. На самом деле, вывод показывает нам name: "Demo", что соответствует значению функции familyFunc. Обратите внимание, что запрос не содержит поля id, даже если преобразователь вернул его. Это правильно, поскольку вызывающая сторона не включила его в запрос GQL-документа.
Все становится интересным, но теперь пора выполнить настоящий SQL-запрос:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Новая реализация familyFunc относительно проста:
- Составьте оператор
sqlдля выполнения. - Запускаем запрос, используя подключение к базе данных через декоратор
context.app.sqlite. - Записать вывод в лог для отладки и вернуть результат.
Поскольку существует соответствие между столбцами таблицы SQL Family и полями объектного типа Family GQL, мы можем вернуть результат, полученный непосредственно из базы данных.
Управление вводом данных пользователем в SQL-запросах
Вы могли заметить, что оператор sql был инстанцирован утилитой шаблонов с метками SQL. Он инициализируется следующим образом: const SQL = require('@nearform/sql'). Модуль @nearform/sql обеспечивает уровень безопасности для работы с пользовательским вводом, защищая нашу базу данных от попыток SQL-инъекций.
Теперь мы можем сделать шаг вперед и прочитать членов семьи. Для этого нам нужно просто изменить тело запроса GQL:
1 2 3 4 5 6 7 8 9 10 | |
Если мы выполним этот запрос, то получим ошибку:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Важно знать, что ответ на ошибку GQL по HTTP всегда имеет статус HTTP 200 и массив errors, в котором перечислены все проблемы, найденные для каждого выполняемого запроса. Фактически, мы можем попытаться запустить несколько запросов с одной полезной нагрузкой:
1 2 3 4 5 6 7 8 9 10 11 | |
Новый фрагмент кода запускает два запроса в рамках одного имени операции. В этом случае обязательно нужно определить алиас, что мы и сделали, добавив <label>: перед объявлением поля. Обратите внимание, что вы можете использовать псевдонимы для настройки имени свойства ответа объекта data. При написании нескольких запросов или мутаций вы должны знать, что запросы выполняются параллельно, а мутации сервер выполняет последовательно.
Ответ на предыдущий GQL-документ будет похож на первый из этого раздела, но обратите внимание на объект data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
В полезной нагрузке ответа содержится псевдоним one с корректным выводом. Вместо этого свойство two является null и имеет соответствующий элемент в массиве errors.
Прочитав сообщение об ошибке, мы можем понять, что сервер возвращает значение null для объектного типа Family, и этот случай конфликтует с members: [Person!]! определением схемы GQL из-за восклицательного знака. Мы определили, что у каждого класса Family есть хотя бы один член, но как их получить? Давайте выясним это в следующем разделе.
Реализация разрешителей объектов типа¶
Нам нужно получить члены объектного типа Family, чтобы правильно реализовать разрешитель family(id: ID!). У нас может возникнуть соблазн добавить еще один запрос к функции familyFunc, которую мы написали в разделе Implementing our first GQL query resolver. Это неправильный подход к работе с GQL. Мы должны стремиться к созданию системы, которая была бы автосогласованной. Это означает, что что бы ни возвращала операция запроса, тип Family не должен знать о своих отношениях, чтобы выполнить их, но тип Family должен знать, что делать. Давайте отредактируем код app.js следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Следующий фрагмент кода должен прояснить, что думает спецификация GQL. Мы добавили резольвер Family.members, используя тот же шаблон для операции корня запроса:
1 2 3 4 | |
Таким образом, если мы прочитаем следующий запрос, то сможем попытаться предсказать выполняемые резолверы:
1 2 3 4 5 6 7 8 9 | |
В этом примере мы можем предсказать следующее:
- Выполняется преобразователь запроса
family, и возвращается типFamily. - Тип
Familyзапускает резольверname. Поскольку мы не определили его, поведение по умолчанию — возврат свойства в том же имени, путем чтения объекта из шага 1. - Тип
Familyзапускает резольверmembers. Поскольку мы его определили, выполняется функцияmembersFunc. В этом случае аргументparent, о котором мы упоминали в разделе Implementing our first GQL query resolver, равен объекту, возвращенному на шаге 1 обработки. Поскольку полеmembersожидает массив типаPerson, мы должны вернуть массивobject, отображающий его структуру. - Тип
Personуправляет резольверами id иfullName. Так как мы их не определили, будет применено поведение по умолчанию, как описано в шаге 2.
На данный момент вы должны быть поражены мощью GQL, и все связи и возможности, которые он предлагает, должны быть вам понятны.
Сейчас я проведу вас немного дальше, потому что мы получаем новую ошибку: Cannot return null for non-nullable field Person.fullName.! Давайте исправим ее с помощью следующей реализации типа Person:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
Как вы можете видеть в предыдущем фрагменте кода, мы реализовали все резольверы полей Person. Функция nickName должна быть вполне понятна: столбец nick в базе данных не соответствует определению схемы GQL, поэтому нам нужно научить адаптер GQL читать соответствующее значение nickName. В резольверах Person.family и Person.friends применяется та же логика, которую мы обсуждали в случае с Family.members. В целях эксперимента в резолвере fullName используется несколько иная бизнес-логика путем конкатенации имен человека и семьи.
Правильный ли это дизайн?
Если вы спросите себя, хорошо ли структурирован наш источник данных, то ответ будет нет. Резольвер fullName спроектирован очень странным образом, чтобы лучше оценить оптимизацию, о которой мы поговорим в следующем разделе.
Теперь, выполнив наш предыдущий HTTP-запрос, он должен работать, как и ожидалось, и мы можем приступить к выполнению сложных запросов, таких как следующий:
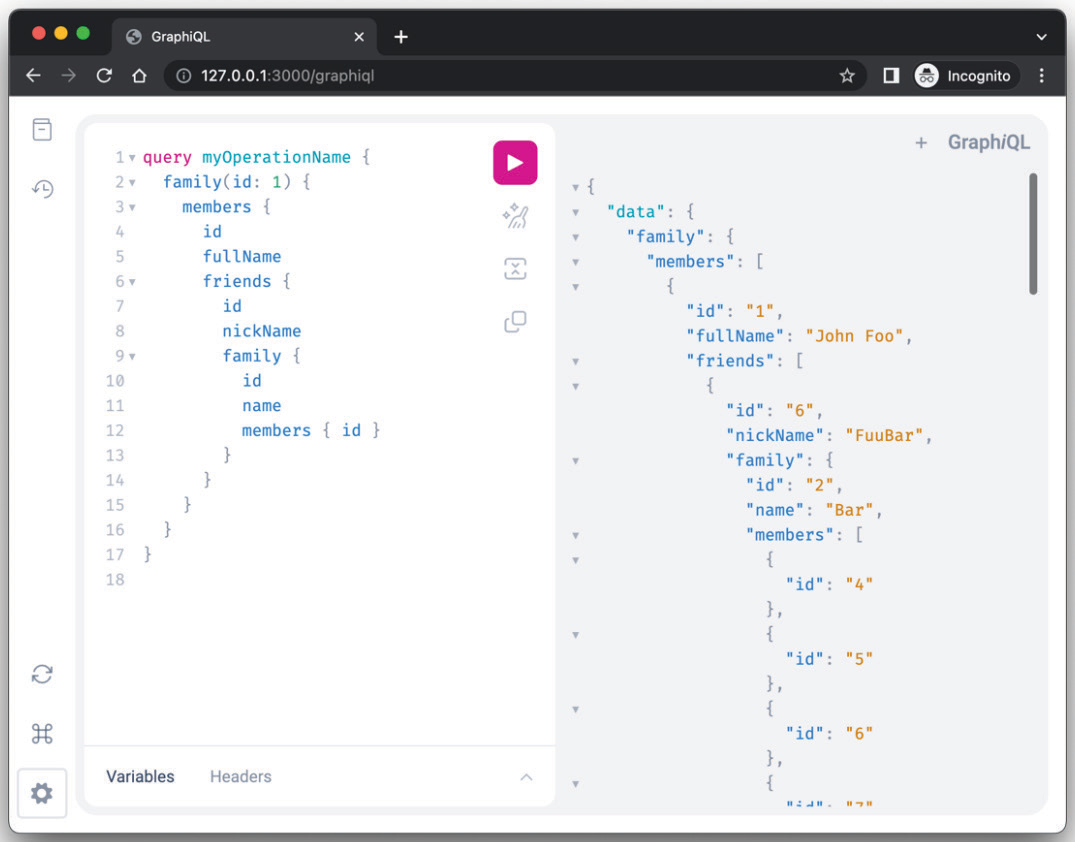
Как видите, теперь можно перемещаться по графу приложения, открытому нашим GQL-сервером, так что можно читать: члены семьи каждого друга, которые есть у каждого члена семьи 1.
Отлично! Теперь вы знаете, как реализовать любой GQL-резольвер, вы должны быть в состоянии самостоятельно реализовать мутации, которые мы определили в разделе Определение GQL-операций. Концепция та же: вам нужно будет добавить свойство Mutation к объекту resolvers в файле app.js. Если вам нужна помощь, вы можете проверить решение, посмотрев URL репозитория главы по адресу https://github.com/PacktPublishing/Accelerating-Server-Side-Development-with-Fastify/tree/main/Chapter%2014.
Вы, наверное, заметили, что наша реализация запускает тонны SQL-запросов к базе данных для одного GQL-запроса! Это совсем не хорошо! Итак, давайте посмотрим, как мы можем это исправить в следующем разделе.
Как улучшить производительность резолвера?¶
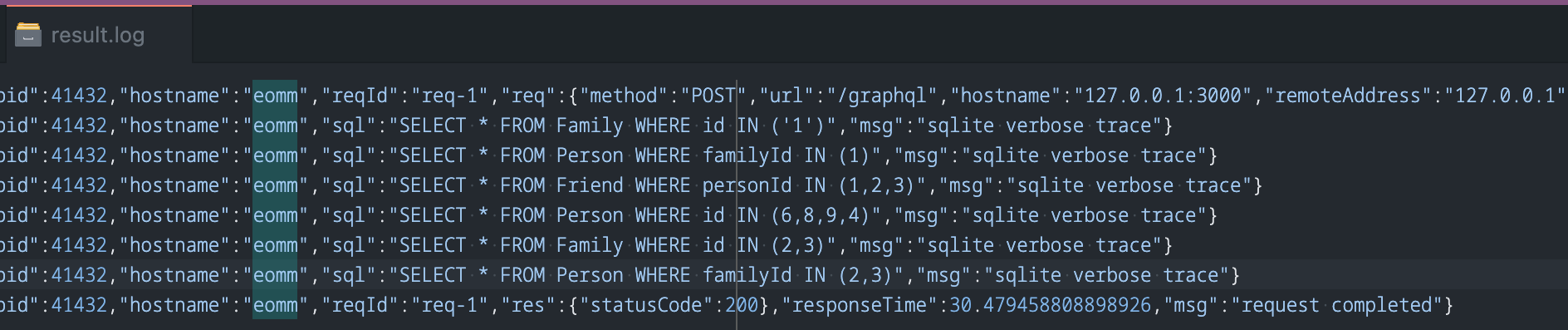
Если мы будем вести лог каждого SQL-запроса, попадающего в нашу базу данных при выполнении GQL-запроса на рисунке 14.4, то насчитаем впечатляющее количество — 18 запросов! Для этого можно обновить конфигурацию плагина SQLite следующим образом:
1 2 3 4 5 | |
С новой конфигурацией вы сможете увидеть все SQL-выполнения, которые были запущены во время разрешения GQL-запроса, а также увидите множество дублирующихся запросов:
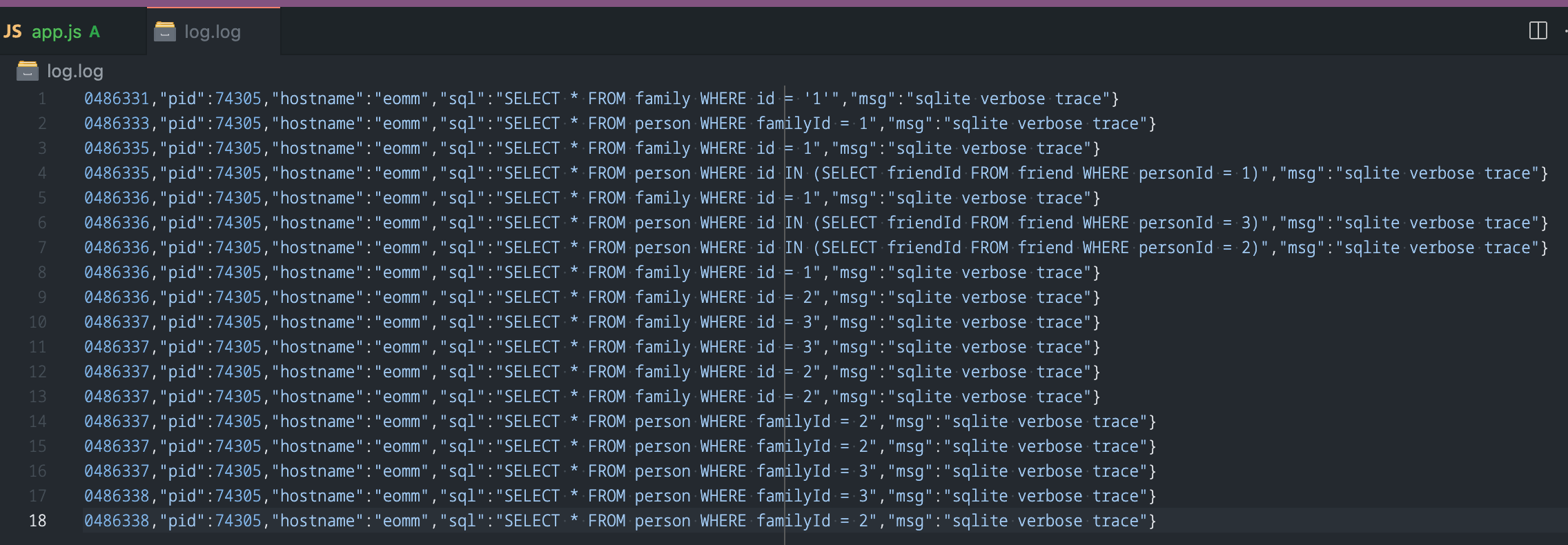
Эта проблема называется N+1 problem, которая снижает производительность сервиса и тратит много ресурсов сервера. Конечно, сервер GraphQL стремится обеспечить простоту над сложностью. Он отказывается от написания больших SQL-запросов с многочисленными соединениями и условиями, чтобы удовлетворить отношения между объектами.
Решением для этого повседневного случая является использование DataLoader. DataLoader — это стандартный механизм загрузки данных, который управляет доступом к источникам данных приложения, выполняя следующие действия:
- Пакетирование: Это агрегирует запросы, выполненные в одном тике цикла событий или в заданном временном интервале, давая вам возможность выполнить один запрос к самому источнику данных
- Кэширование: Кэширование результатов запросов для каждого GQL-запроса, так что если вы читаете один и тот же элемент несколько раз, вы прочитаете его из источника данных один раз
Реализация DataLoader API обеспечивается модулем dataloader npm, который можно установить, выполнив команду npm install dataloader. Давайте посмотрим, как его использовать после добавления в наш проект.
Первым шагом будет создание нового файла data-loaders/family.js со следующим кодом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Мы создали фабричную функцию buildDataLoader, которая создает новый экземпляр DataLoader, требующий аргумента функции. Реализация довольно проста, поскольку на вход мы получаем массив ids, который можно использовать для составления SQL-запроса с условием IN.
Метод SQL.glue
Обратите внимание, что для выполнения простого условия SQL IN нам пришлось написать немного больше кода. Это необходимо, потому что SQLite не поддерживает параметры массива, как вы можете прочитать в официальном репозитории. Функция SQL.glue позволяет нам конкатенировать массив идентификаторов без потери проверок безопасности, реализованных модулем @nearform/sql.
Наиболее важной логикой, на которую следует обратить внимание, является этап ids.map(). Функция fetcher должна возвращать массив результатов, каждый элемент которого соответствует порядку входных идентификаторов. Еще одним важным моментом является опция cacheKeyFn. Поскольку DataLoader может быть вызван с помощью строковых или числовых идентификаторов, приведение всех значений к строкам позволит избежать неприятных несовпадений из-за типа данных аргумента — по той же причине мы применяем защиту типа при выполнении familyData.find().
Теперь вы должны быть в состоянии реализовать файлы data-loaders/person.js, data-loaders/person-by-family.js и data-loaders/friend.js, используя тот же шаблон.
Мы почти завершили интеграцию. Теперь мы должны добавить DataLoaders в контекст GQL-запроса, поэтому нам нужно еще немного отредактировать конфигурацию Mercurius:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Мы можем расширить стандартный аргумент контекста, вводимый в каждую функцию резолвера, задав параметр Mercurius context.
Последний шаг — обновление резолверов приложения. Каждый резолвер должен прочитать данные, используя DataLoaders, сохраненный в параметре context. Вот окончательный результат:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
В предыдущем фрагменте кода вы можете увидеть несколько примеров использования DataLoader'ов. Каждый DataLoader предлагает две функции, load и loadMany для чтения одного или нескольких элементов. Теперь, если мы прочитаем лог SQLite, то увидим, что количество запросов сократилось на две трети!
Приложение GraphQL было оптимизировано! Вы узнали наиболее гибкий и стандартный способ повышения производительности реализации GQL. Мы должны упомянуть, что Mercurius поддерживает опцию конфигурации загрузчика. Она менее гибкая, чем DataLoader, но вы можете углубиться в эту тему, прочитав следующую запись в блоге.
Теперь мы рассмотрим последнюю тему этой главы, чтобы получить полное представление о создании GQL-сервера с помощью Fastify и Mercurius: как работать с ошибками?
Управление ошибками GQL¶
Спецификация GraphQL определяет формат ошибки. Пример этого мы видели в разделе Реализация нашего первого распознавателя GQL-запросов. Общими свойствами являются:
message: Описание сообщенияlocations: Координаты документа GraphQL-запроса, вызвавшего ошибкуpath: Поле ответа, в котором произошла ошибкаextensions: Необязательное поле для включения пользовательских свойств вывода
В Mercurius мы можем настраивать ошибку message, бросая или возвращая объект Error:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Если мы хотим расширить поле элементов errors, мы должны следовать спецификации, используя поле extensions. Чтобы сделать это с помощью Mercurius, мы должны использовать расширение объекта Error. Мы можем заменить предыдущий фрагмент кода следующим новым:
1 2 3 4 5 6 | |
Используя объект ErrorWithProps, мы можем добавить столько свойств, сколько нам нужно, в поле extensions.
Наконец, мы должны знать, что Fastify и Mercurius управляют необработанными ошибками в нашем приложении, чтобы избежать утечек памяти и падений сервера. Эти ошибки могут содержать конфиденциальную информацию, поэтому мы можем добавить опцию errorFormatter для их обфускации:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Функция errorFormatter вызывается только тогда, когда сервер возвращает не пойманные ошибки. Функция hideSensitiveData проверяет, является ли ошибка действительной ошибкой приложения или общей. Если это последняя, мы должны переписать сообщение об ошибке, чтобы сохранить метаданные locations и path. Обратите внимание, что все элементы result.errors являются экземплярами класса GraphQLError, поэтому мы должны различать ошибки приложения с помощью поля extensions.
Отлично! Мы рассмотрели все возможные особенности обработки ошибок, чтобы построить надежную и однородную систему реагирования и управления ошибками.
Резюме
Эта глава была плотным и интенсивным учебным лагерем по миру GraphQL. Теперь у вас есть прочная базовая теория для понимания экосистемы GQL и того, как она работает под капотом каждого GQL-адаптера.
Мы построили GraphQL-сервер с нуля, используя Fastify и Mercurius. Все знания, полученные из Главы 1 этой книги, актуальны, потому что у приложения Fastify больше нет секретов для вас.
В дополнение к знаниям о Fastify вы можете определить схему GQL и реализовать ее резольверы. Мы решили проблему N+1 и теперь знаем, как правильно с ней справиться и создать быстрое и надежное приложение.
Наконец-то в вашем распоряжении полный набор инструментов для создания отличных API. Вы готовы еще больше улучшить свою кодовую базу, внедрив TypeScript в следующей главе!